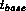 .
All processors expand the nodes of their local array up to the current search-threshold.
Since the size of the subtrees emanating from the nodes
is not known a priori, dynamic load balancing is required.
.
All processors expand the nodes of their local array up to the current search-threshold.
Since the size of the subtrees emanating from the nodes
is not known a priori, dynamic load balancing is required.
The following iterations start on the frontier nodes .
All processors expand the nodes of their local array up to the current search-threshold.
Since the size of the subtrees emanating from the nodes
is not known a priori, dynamic load balancing is required.
Our implementation of AIDA* employs a simple task attraction scheme.
The 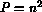 processing elements are connected in a
processing elements are connected in a 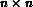 torus
topology (i.e. a mesh with wrap-around links in the rows and columns).
Each processor is a member of two rings with
torus
topology (i.e. a mesh with wrap-around links in the rows and columns).
Each processor is a member of two rings with  elements: the horizontal
and the vertical ring.
elements: the horizontal
and the vertical ring.
A processor first expands its local frontier nodes of level .
When running out of work, it sends a work_request
in clockwise order along the horizontal link of the torus.
The first processor with unexpanded frontier nodes in its array
sends a work packet back to the requester.
If none of the processors on the horizontal ring has work to share,
the request continues its path along the ring
and eventually returns to the requester,
indicating that the current iteration run out of work on this horizontal ring of the torus.
The requester now sends a work request
along the vertical ring using the same mechanism.
If again no processor responds with a work packet,
an out_of_work message is sent on both rings
and this processor starts the next iteration.
We call this a weak synchronization -
as opposed to a hard barrier synchronization.
It keeps all processors working at about the same iteration, while not
requiring too much idle time [Newborn, 1988].
In practice, our weak synchronization works much like a majority consensus approach.
When searching for a first solution, care must be taken that all processors
working on shallower iterations finish their
search before returning the optimal solution.
Note, that any work package is exclusively owned by a single processor. Whenever a package is transferred to another processor, it changes ownership. This is done with the expectation that all subtrees grow at about the same rate from one iteration to the next. Hence, the load balance will automatically improve during the search. In fact, the number of work packets decreases with increasing search time (cf., Fig. 7).