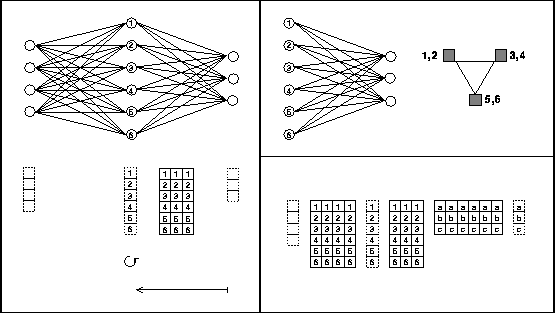
Figure 3: Parallel on-line backward propagation
The alternative to on-line training is batch learning. For parallel batch learning the training set is divided and learned separately with some identical copies of the net in parallel. The weight corrections are summed up and globally corrected in all nets after each epoch (cf. Figure 4).
Figure 3: Parallel on-line backward propagation
Communication is only necessary for the calculation of the global sum of the weight corrections after each epoch. In addition to this a global broadcast has to be performed after the master node has calculated the random numbers for the new weights after splitting, but this happens very rarely.
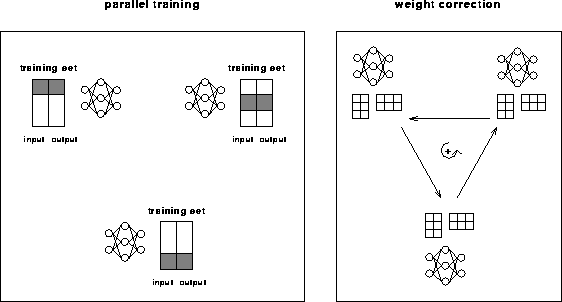
Figure 4: Parallel batch learning
The batch learning is different from the on-line training concerning the convergence speed and the quality of approximation.