- Ergebnisse
- Analyse der Datenreihen
- Die CO2-Datenreihe
- Saisonale Periodizität
Eine Aggregation der Monatswerte der CO2-Konzentration über die Jahre 1992 bis 1996 ergab eine deutliche Periode, wie auch Abbildung 4.1 zu entnehmen ist.
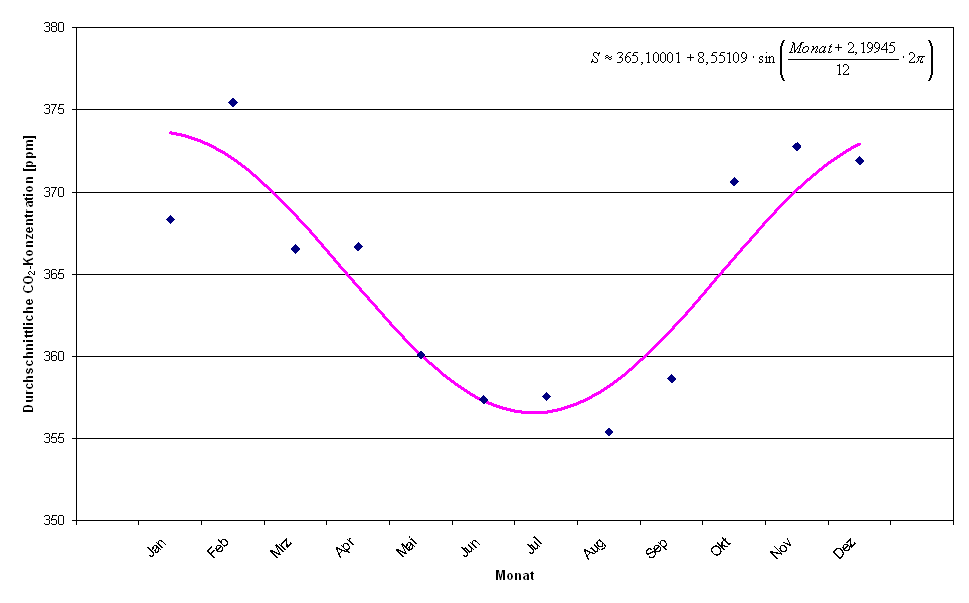
Abbildung .1: Monatliche CO2-Konzentration (Durchschnitt der Jahre 1992 - 1996)
Bei der Bestimmung der Saisonkomponente wurden die Monatsmittelwerte über alle Jahre verwandt und eine Periode von zwölf Monaten vorausgesetzt. Die Modellgleichung lautet:
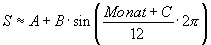
Dabei entspricht A dem Mittelwert, um den die Werte schwanken, B einem Faktor, der die Amplitude der Schwingung darstellt und C der zeitlichen Verschiebung der Amplitude. Die Methode der kleinsten Abweichungsquadrate ergab folgende Werte für die Konstanten:
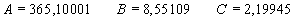
Somit erhält man
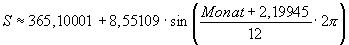 .
.
- Trend
Abbildung 4.2 zeigt den linearen Trend der CO2-Datenreihe über die Jahre 1992 bis 1996.
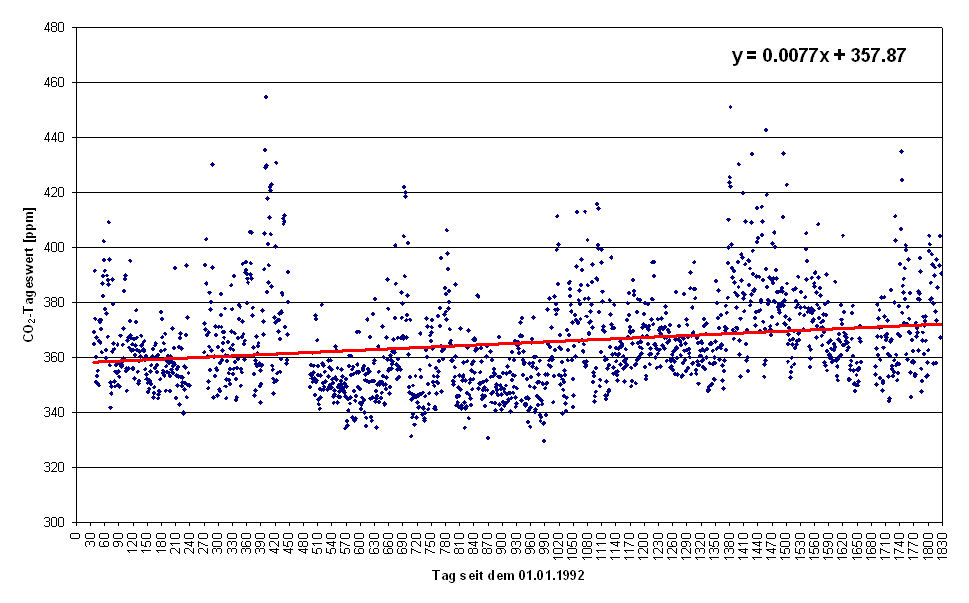
Abbildung .2: Linearer Trend der CO2-Konzentration über die Jahre 1992 bis 1996
Diese Trendbetrachtung zeigt zudem einen Anstieg der durchschnittlichen jährlichen CO2-Konzentration von ca. 2,8124 ppm.
- Autokorrelation
Viele natürliche Zeitreihen sind autokorreliert, d.h., es besteht ein Zusammenhang zwischen zeitlich aufeinander folgenden Meßwerten. Die Autokorrelation entspricht dem Korrelationskoeffizienten zwischen der Zeitreihe und der zeitlich verschobenen bzw. geshifteten Zeitreihe. Eine hohe Autokorrelation spricht für die Verwendung der geshifteten Zeitreihe im (linearen) Modell, also für Autoregressive Ansätze, wie sie definitionsgemäß bei ARIMA-Modellen zu finden sind. Trägt man die Autokorrelationen gegen die Shifts auf, erhält man ein sogenanntes Korrelogramm. Mit Hilfe des Korrelogramms können Periodizitäten - falls vorhanden - identifiziert werden. Abbildung 4.3 zeigt das Korrelogramm der CO2-Datenreihe für die Shifts 0 bis 10.
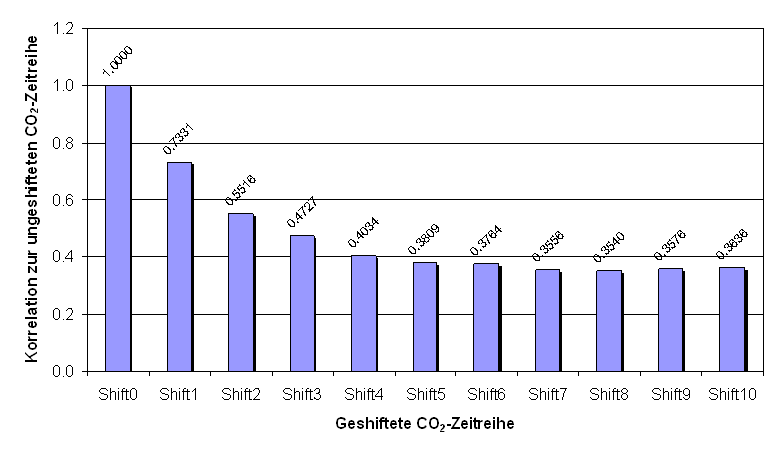
Abbildung .3: Korrelogramm der CO2-Zeitreihe
Die hohe Autokorrelation für den Meßwert vom Vortag (Shift 1) und dem Tag davor (Shift 2) im Vergleich zur Korrelation zu den anderen Zeitreihen (siehe Kapitel 4.1.2), lassen eine Verwendung der geshifteten Zeitreihen bei der Modellierung sinnvoll erscheinen.
Anhand des Korrelationskoeffizienten nach Pearson-Spearman lassen sich im Vorfeld günstige exogene Zeitreihen für die (lineare) Modellierung identifizieren. Dabei ist der Absolutbetrag des Korrelationskoeffizienten entscheidend. Tabelle 4.1 zeigt die Korrelationskoeffizienten der CO2-Zeitreihe mit den anderen zur Verfügung stehenden Datenreihen.
Tabelle .1: Korrelationen zur CO2-Zeitreihe, nach absolutem Wert geordnet

In Kapitel 4.1.1.4 wurden die Korrelationen der CO2-Zeitreihe mit anderen Zeitreihen als ein Weg beschrieben, eine mögliche Vorauswahl der Daten für ein Modell zu treffen. Es ist allerdings zu beachten, daß zwischen Zeitreihen, die zu den CO2-Daten hoch korreliert sind, auch untereinander große Korrelationen bestehen können, die eine Verwendung im Modell u.U. redundant machen. Man spricht in diesem Fall von verborgenen Korrelationen. Ein natürliches Beispiel dafür sind die Bedeckungsgrad-Zeitreihe (BG) und die Sonnenscheindauer-Zeitreihe (SSD).
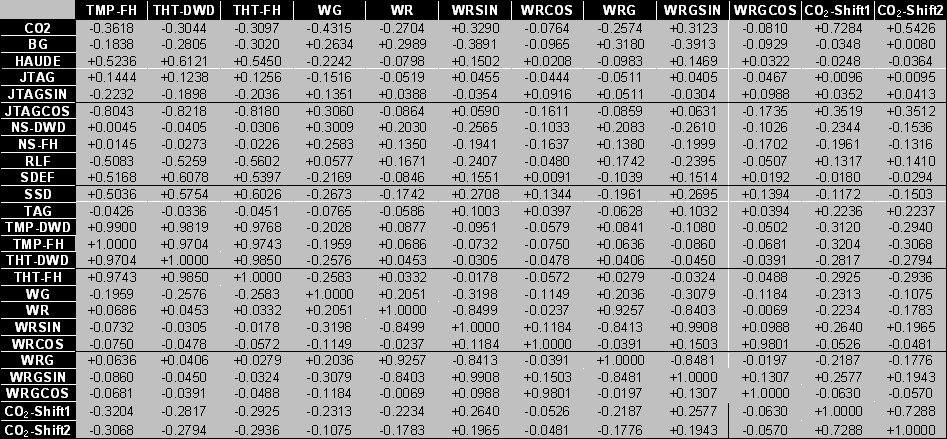
Um einen Überblick über die Korrelationen der Zeitreihen untereinander zu erhalten, werden oftmals sogenannte Korrelationsmatrizen aufgestellt, die die Korrelation jeder Zeitreihe mit allen anderen zeigen. Eine ausführliche Korrelationsmatrix ist in Tabelle 4.2 (Teil 1) und Tabelle 4.3 (Teil 2) gegeben.
Tabelle .2: Korrelationsmatrix (Teil 1)
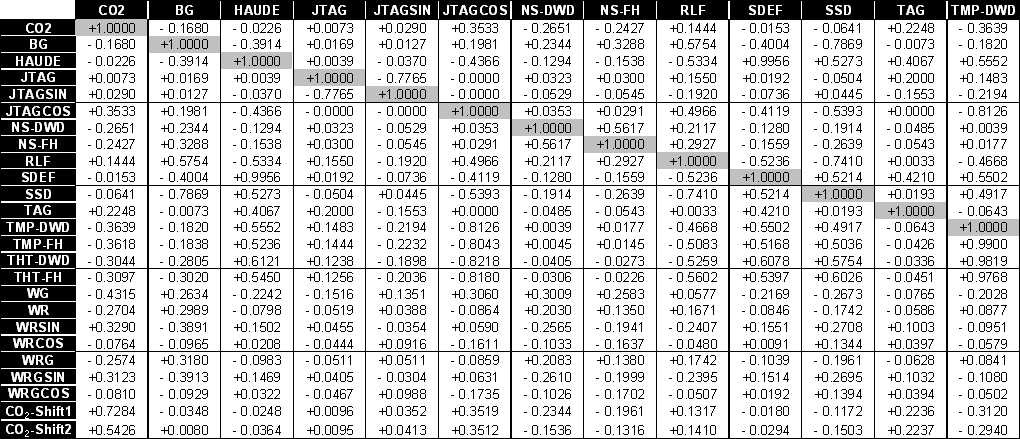
Tabelle .3: Korrelationsmatrix (Teil 2)
Neben der Bestimmung von linearen Einflüssen kann die neuronale Sensitivitätsanalyse dazu herangezogen werden, nichtlineare Abhängigkeiten zu erkennen. Dazu wird ein Neuronales Netz mit allen möglichen exogenen Variablen trainiert und die Sensitivität der einzelnen Input-Neuronen bestimmt. Theoretisch kann aus der Gewichtung der Einfluß der entsprechenden Neuronen auf das neuronale Modell abgelesen werden. Abbildung 4.4 zeigt eine solche Sensitivitätsanalyse. Größere Spannweiten deuten auf eine größere Bedeutung der einzelnen Neuronen hin.
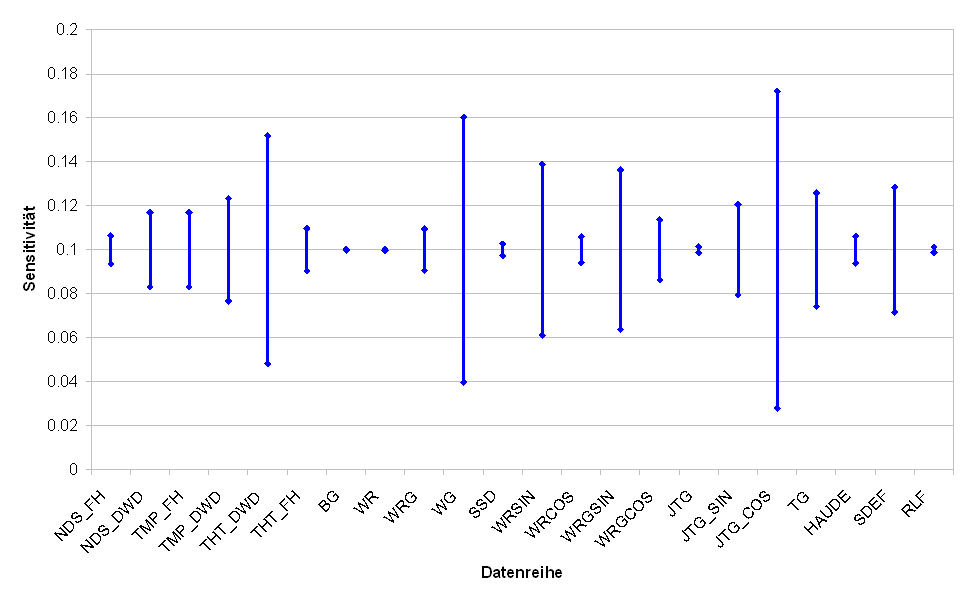
Abbildung .4: Neuronale Sensitivitäten der einzelnen exogenen Parameter
Vorgehen
Für die vergleichende Analyse der Neuronalen Netze und mathematischen Modelle wurden verschiedene Prognose- bzw. Analysezeiträume gewählt, um ein möglichst umfassendes Bild über die Analyse- und Prognosefähigkeiten der einzelnen Verfahren zu gewinnen.
Aufgrund ihres modularen Aufbaus sind Neuronale Netze trotz ihrer relativ einfach strukturierten Elemente in der Lage, komplexe Wirkzusammenhänge zu lernen und wiederzugeben. Einfache mathematische Modelle, wie etwa die multiple lineare Regression (siehe Abschnitt 3.1.1), können durch bestimmte Netzstrukturen exakt abgebildet werden. Dazu wird auf verborgene Schichten verzichtet und die Input-Schicht direkt mit dem einzigen Neuron der Output-Schicht verbunden. Als Aktivierungs- und Ausgabefunktion wird die Identität id() verwandt. Werden die exogenen Zeitreihen unskaliert verwendet, so entspricht die Gewichtsmatrix (wij, hier jedoch nur ein Vektor wi) den Faktoren ai der gelösten Regressionsgleichung. Soll eine Regression mit Konstante (a0) nachgebildet werden, so muß ein weiteres Inputneuron mit dem konstanten Wert 1 hinzugefügt werden. Das Gewicht w0 entspricht dann der Konstante a0 der Regressionsgleichung. Abbildung 4.5 zeigt ein solches Netz, wobei das einzige Neuron im eigentlichen Sinn das der Ausgabeschicht ist. Eine äquivalente Netztopologie ist auch mit einem einzelnen Hidden-Neuron möglich.
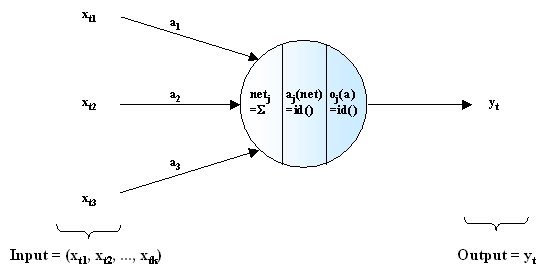
Abbildung .5: Repräsentierung der linearen Regression als Neuronales Netz
Aufgrund dieser Überlegungen wird klar, daß Neuronale Netze potentiell komplexere Zusammenhänge darstellen können als es die Regression kann, zumal bereits die Hinzunahme von Shortcut-Verbindungen und einem konstanten Eingabeneuron ein beliebiges Netz um die Funktionalität der multiplen linearen Regression erweitert. Folglich muß erwartet werden, daß Neuronale Netze in der Analyse und Prognose bessere Ergebnisse erzielen als die multiple lineare Regression.
Für eine repräsentative Aussage bezüglich des Analyse- und Prognosezeitraums wurden sechs verschiedene Zeiträume aus dem Jahr 1996 gewählt, die unterschiedliche saisonale Gegebenheiten repräsentieren. Das Hauptaugenmerk liegt dabei auf der Vegetation, die einen puffernden Effekt auf die CO2-Konzentration ausübt, und auf der Temperatur. Bei niedrigeren Temperaturen ist mit erhöhten Kohlendioxid-Emissionen aufgrund vermehrter Heizleistung zu rechnen, während bei extrem hohen Temperaturen durch Kühlung entsprechende Emissionen hervorgerufen werden können. Insgesamt werden sechs Zeiträume von 30 validen Tagen verwendet, die in jeweils zwei benachbarten Monaten des letzten Jahres des Datenbestandes (1996) liegen (Januar/Februar, März/April, etc.). Auf diese Weise soll den unterschiedlichen saisonalen Gegebenheiten Rechnung getragen werden.
Der untersuchte Zeitraum besteht aus den letzten 15 validen Tagen des ersten und aus den ersten 15 validen Tagen des zweiten Monats. Eine Übersicht über die Zeiträume findet sich in Tabelle 4.4. Es wird jeweils eine Analyse und eine Prognose durchgeführt. Für eine Analyse stehen die Werte der exogenen Zeitreihen zur Zeit des zu prognostizierenden Datums zur Verfügung. Vorherige Werte der CO2-Zeitreihe fließen dabei nicht ein. Bei einer Prognose wird davon ausgegangen, daß die Werte der exogenen Zeitreihe zum Prognosezeitpunkt nicht zur Verfügung stehen. Es wird daher auf die entsprechenden Vortageswerte zurückgegriffen. Hier fließt allerdings auch die CO2-Konzentration vom Vortag mit in die Modelle ein.
Tabelle .4: Übersicht über die untersuchten Zeiträume
|
Monate |
untersuchter Zeitraum |
Fehlwerte |
|
Januar/Februar |
17.01.96-15.02.96 |
keine |
|
März/April |
16.03.96-15.04.96 |
26.03.96 |
|
Mai/Juni |
17.05.96-15.06.96 |
keine |
|
Juli/August |
01.07.96-28.08.96 |
16.07.96-13.08.96 |
|
September/Oktober |
16.09.96-15.10.96 |
keine |
|
November/Dezember |
16.11.96-16.12.96 |
01.12.96 |
Folgende jahreszeitliche Einflüsse werden erwartet:
Im Sommer entfallen die CO2-Emissionen durch das Heizen fast völlig, werden aber evtl. in geringem Maße durch Kühlungsemissionen ausgeglichen. Die Vegetation ist voll entwickelt und durch regelmäßige Sonneneinstrahlung zu erhöhter Photosynthese-Leistung fähig. Es kann also von vergleichsweise niedrigen CO2-Konzentrationen mit geringen Schwankungen ausgegangen werden.
Der Winter zeigt das genaue Gegenteil: Vermehrte CO2-Emissionen während der Heizperiode und eine fast gänzliche Inaktivität der noch vorhandenen Vegetation, die somit auch ihre puffernde Funktion nicht mehr wahrnehmen kann. In dieser Zeit treten vermehrt hohe CO2-Konzentrationen in der Luft auf, und lokale Emissionen spielen eine wichtigere Rolle.
Frühling und Herbst sind als Perioden zunehmender bzw. abnehmender Vegetation zu betrachten, die noch nicht bzw. nicht mehr ihre volle Photosynthese-Leistung bringen. Lokale Emissionen durch Heizen sind höher als im Sommer, aber niedriger als im Winter zu erwarten.
Wie bereits in Kapitel 3.4 erwähnt, zeichnet sich ein Modell neben einer guten Analyse- bzw. Prognoseleistung auch durch eine geringe Zahl exogener Variablen, also Zeitreihen aus. Es wird versucht, eine Beschränkung auf die wichtigen vorzunehmen. In dem hier durchgeführten Vergleich der Verfahren wurden Modelle mit vier exogenen Zeitreihen eingesetzt. Dabei wurden alle Zeitreihen gleichwertig behandelt.
Um eine Vorauswahl für die multiple lineare Regression und das klassische Komponentenmodell zu treffen, wurden lineare Regressionen aller denkbaren Kombinationen von vier aus den 22 bzw. 23 möglichen exogenen Zeitreihen exemplarisch für den Zeitraum vom 12.11.96 bis zum 31.12.96 durchgeführt. Die verschiedenen Läufe wurden anschließend nach RMSE sortiert. Für jede exogene Zeitreihe konnte nun die Position des ersten Auftretens in den sortierten Listen bzw. die durchschnittliche Position (Index) bestimmt werden. Auf diese Weise wurden die 14 einflußreichsten Zeitreihen als exogene Zeitreihen für den Vergleich ausgewählt. Die möglichen Kombinationen wurden so von 7315 auf 1001 reduziert. Tabelle 4.5 zeigt eine Übersicht über die Ergebnisse des Verfahrens.
Tabelle .5: Übersicht über den Einfluß exogener Zeitreihen auf die Regression
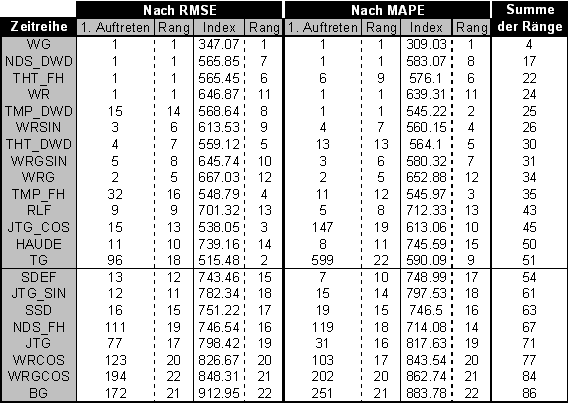
Unter Berücksichtigung der langen Rechenzeiten für ein Netztraining war es im Rahmen dieser Arbeit nicht möglich, ein ähnlich aufwendiges Verfahren zur Identifizierung günstiger Kombinationen exogener Zeitreihen zu finden. Aufgrund dieser Tatsache und aus der Überlegung der prinzipiellen Überlegenheit Neuronaler Netze und des Komponentenmodells gegenüber der Regression wurde für diese Verfahren die jeweils beste Kombination der Regression genutzt.
Für die Neuronalen Netze beschränkt sich die Optimierung also auf die Netzarchitektur. Variationsmöglichkeiten bestanden insbesondere bei der Wahl der Lernfunktion (BP_momentum, BPM_ln_cosh und Rprop), bei der Modifikation der Architektur (keine, Vorschicht, Shortcuts oder Vorschicht und Shortcuts) sowie bei der Skalierung der Zeitreihen (LIN, SIG4, SIG4CUT, SIG4CUT0).
Neben der Auswahl geeigneter Einflußzeitreihen hat bei den Neuronalen Netzen auch die Auswahl einer günstigen Netztopologie einen wesentlichen Einfluß auf die Prognose- und Analysegüte. Ausgehend von einer Grundkonfiguration werden verschiedene Komponenten variiert und die möglichen Kombinationen auf ihre Güte getestet. Die Einstellungen, die für alle Läufe gleich waren (Grundkonfiguration), werden in Tabelle 4.6 aufgeführt. Ziel ist es, aufgrund der exemplarischen Ergebnisse mit allen vernünftig erscheinenden Parametern eine Einschränkung der freien Variablen für Strukturfindung bei der tatsächlichen Analyse bzw. Prognose vorzunehmen.
Tabelle .6: Grundkonfiguration zur Bestimmung der günstigsten Netzparameter

Folgende vier Komponenten wurden variiert:
Die Standardlernfunktion BackpropMomentum wurde mit Resilent Propagation (Rprop) und BackpropMomentum mit ln(cosh()) als Fehlerfunktion (BPM_ln_cosh) verglichen.
Für die Verwendung einer Zeitreihe im Rahmen eines neuronalen Modells ist die Skalierung auf den verwendeten Wertebereich (hier: ]-1..+1[) sinnvoll. Zum Einsatz kamen die lineare Skalierung (LIN), sowie die m
-s
-Skalierungen MY_SIGMA4, MY_SIGMA4CUT und MY_SIGMA4CUT0.
- Modifikationen der Topologie
Neben der Standardtopologie (Feed Forward Multi Layer Perzeptron) wurden Shortcut-Verbindungen von der Input- zur Output-Schicht (shortC) verwendet sowie die Vorschicht (vorS) und eine Kombination aus Vorschicht und SC-Verbindungen (von der Hidden-Schicht zur Output-Schicht). Eine Erläuterung der Modifikationen findet sich in Abschnitt 3.2.1.3.
- Anzahl der Neuronen in der verborgenen Schicht
Für die Hidden-Schicht wurden 3 bis 10 Neuronen getestet.
Die fünf günstigsten Parametereinstellungen werden in Tabelle 4.7 (Analyse) und Tabelle 4.8 (Prognose) aufgeführt. Eine Gesamtübersicht über die Läufe findet sich im Anhang (Kapitel 7.1 und 7.2.1).
Tabelle .7: Die 5 günstigsten Topologien für die Analyse (nach RMSE)

Tabelle .8: Die 5 günstigsten Topologien für die Prognose (nach RMSE)

Aufgrund der Ergebnisse wurden Lernfunktionen auf BP_momentum und BPM_ln_cosh beschränkt und die Skalierungsfunktionen auf linear und m
-s
-Skalierung. Für die Anzahl der Neuronen in der Hidden-Schicht wurden 3, 5, 7 und 10 ausgewählt und als Topologie-Modifikationen blieben keine, Vorschicht und Vorschicht mit Shortcuts. Somit waren für jede Analyse / Prognose nur noch 48 Netz-Trainingsläufe mit einem geschätzten Zeitaufwand von jeweils ca. 16 Stunden nötig.
- Vergleich der Verfahren
Bei den betrachteten sechs Zeiträumen und der Unterscheidung von Analyse und Prognose werden insgesamt 12 Vergleiche durchgeführt. Jeder Vergleich umfaßt einen Vergleich der Fehler (nach RMSE, in Kapitel 3.3 erläutert). Eine Sonderstellung hat hier das ARIMA-Modell, welches nur für den Fall eines zusammenhängenden Prognosezeitraums mit ausreichend Werten davor eingesetzt werden kann.
Für die Regressionsmodelle werden die bei 4 aus 15 exogenen Zeitreihen möglichen 1001 Kombinationen getestet und die beste für den Vergleich verwandt. Die so gefunden Kombinationen werden auch von den anderen Verfahren (SNNS, Komponentenmodell) verwandt.
Analyse
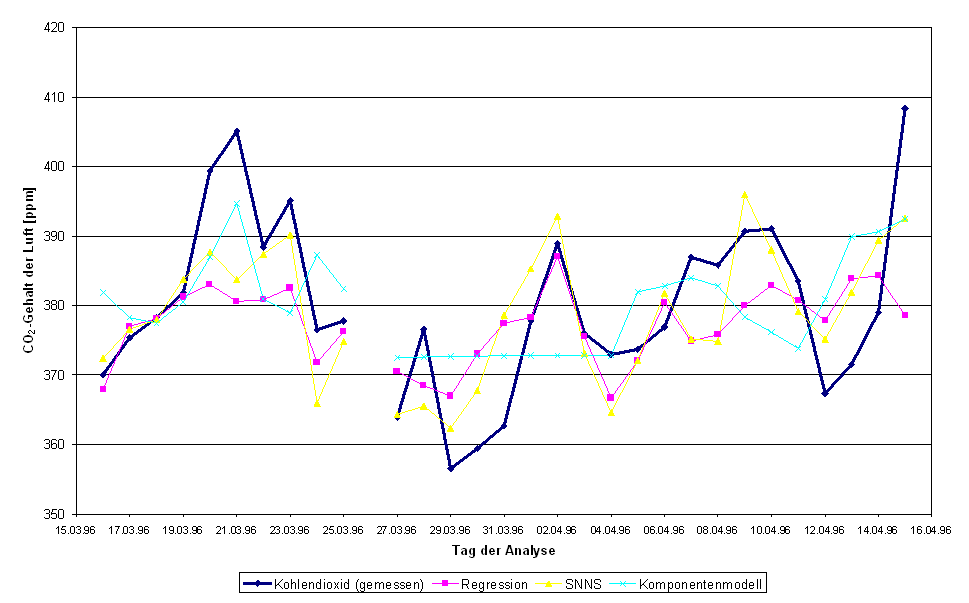
Abbildung .6: Vergleich der Analysegüte der drei Verfahren (Zeitraum März / April 1996)
- Januar / Februar
Die fünf günstigsten Kombinationen exogener Zeitreihen für den Analysezeitraum können Tabelle 4.9 entnommen werden.
Tabelle .9: Günstigste Kombinationen exogener Zeitreihen für die Analyse (Januar/Februar 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Exogene Variablen |
|
902 |
2.0443 |
0.0206 |
3437.2 |
10.704 |
0.6335 |
TMP_DWD THT_DWD WG WR |
|
810 |
2.0002 |
0.0200 |
3440.7 |
10.709 |
0.6338 |
TG TMP_DWD WG WR |
|
903 |
1.9694 |
0.0199 |
3471.9 |
10.758 |
0.6367 |
TMP_DWD THT_DWD WG WRSIN |
|
221 |
2.0107 |
0.0203 |
3474.7 |
10.762 |
0.6369 |
HAUDE TMP_DWD WG WR |
|
811 |
1.9359 |
0.0194 |
3475.7 |
10.764 |
0.6370 |
TG TMP_DWD WG WRSIN |
Tabelle .10: Die fünf günstigsten Netzarchitekturen für die Analyse (Januar/Februar 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Lernfunktion |
Skal.-Fkt. |
Hidden |
Topologie Mod. |
|
25 |
1.9770 |
0.0196 |
2534.3 |
9.1912 |
0.544 |
BPM_ln_cosh |
linear |
7 |
none |
|
28 |
1.7213 |
0.0172 |
2623.8 |
9.3520 |
0.5535 |
BPM_ln_cosh |
linear |
3 |
vorS+shortC |
|
27 |
1.8825 |
0.0187 |
2769.8 |
9.6087 |
0.5687 |
BPM_ln_cosh |
linear |
10 |
vorS |
|
5 |
1.8426 |
0.0184 |
2962.1 |
9.9366 |
0.5881 |
BP_momentum |
linear |
5 |
vorS+shortC |
|
31 |
1.9492 |
0.0192 |
2980.9 |
9.9681 |
0.5899 |
BPM_ln_cosh |
linear |
7 |
vorS+shortC |
Tabelle .11: Gegenüberstellung der Modellergebnisse (Januar/Februar 1996)
|
Modell |
mape |
rmse |
|
SNNS |
1.9770 |
9.191 |
|
Komponentenmodell |
2.0102 |
9.350 |
|
Regression |
2.0443 |
10.704 |
- März / April
Tabelle .12: Günstigste Kombinationen exogener Zeitreihen für die Analyse (März/April 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Exogene Variablen |
|
193 |
2.0911 |
0.0211 |
3403.1 |
10.651 |
0.9713 |
HAUDE TG WG WR |
|
195 |
2.1394 |
0.0216 |
3485.9 |
10.780 |
0.9822 |
HAUDE TG WG WRG |
|
194 |
2.1571 |
0.0218 |
3573.5 |
10.914 |
0.9806 |
HAUDE TG WG WRSIN |
|
196 |
2.1882 |
0.0221 |
3688.2 |
11.088 |
0.9962 |
HAUDE TG WG WRGSIN |
|
698 |
2.2067 |
0.0224 |
3887.3 |
11.383 |
1.0438 |
RLF TG WG WR |
Tabelle .13: Die fünf günstigsten Netzarchitekturen für die Analyse (März/April 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Lernfunktion |
Skal.-Fkt. |
Hidden |
Topologie Mod. |
|
27 |
1.9412 |
0.0194 |
2181.4 |
8.6730 |
0.7791 |
BPM_ln_cosh |
linear |
10 |
vorS |
|
28 |
1.7794 |
0.0178 |
2183 |
8.6762 |
0.7835 |
BPM_ln_cosh |
linear |
3 |
vorS+shortC |
|
4 |
1.7725 |
0.0177 |
2201.7 |
8.7133 |
0.7868 |
BP_momentum |
linear |
3 |
vorS+shortC |
|
13 |
1.9057 |
0.019 |
2226 |
8.7612 |
0.7908 |
BP_momentum |
m
-s
|
7 |
none |
|
25 |
1.8211 |
0.0181 |
2267.6 |
8.8428 |
0.7927 |
BPM_ln_cosh |
linear |
7 |
none |
Tabelle .14: Gegenüberstellung der Modellergebnisse (März/April 1996)
|
Modell |
mape |
rmse |
|
SNNS |
1.9412 |
8.673 |
|
Komponentenmodell |
1.8870 |
10.264 |
|
Regression |
2.0911 |
10.651 |
- Mai / Juni
Tabelle .15: Günstigste Kombinationen exogener Zeitreihen für die Analyse (Mai/Juni 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Exogene Variablen |
|
666 |
1.4651 |
0.0147 |
1744.2 |
7.625 |
0.6099 |
NDS_DWD WG WRSIN WRGSIN |
|
1000 |
1.5503 |
0.0156 |
1920.9 |
8.002 |
0.6400 |
WG WRSIN WRG WRGSIN |
|
998 |
1.5525 |
0.0156 |
1926.7 |
8.014 |
0.6410 |
WG WR WRSIN WRGSIN |
|
586 |
1.6513 |
0.0165 |
1963.2 |
8.089 |
0.6470 |
NDS_DWD TG WRSIN WRGSIN |
|
665 |
1.5225 |
0.0153 |
1984.1 |
8.132 |
0.6504 |
NDS_DWD WG WRSIN WRG |
Tabelle .16: Die fünf günstigsten Netzarchitekturen für die Analyse (Mai/Juni 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Lernfunktion |
Skal.-Fkt. |
Hidden |
Topologie Mod. |
|
12 |
1.5563 |
0.0156 |
1585.6 |
7.2699 |
0.5814 |
BP_momentum |
linear |
5 |
none |
|
34 |
1.4839 |
0.0148 |
1604 |
7.3121 |
0.5848 |
BPM_ln_cosh |
linear |
7 |
vorS |
|
9 |
1.5825 |
0.0159 |
1606.2 |
7.3171 |
0.5852 |
BP_momentum |
linear |
10 |
none |
|
23 |
1.5549 |
0.0155 |
1640.3 |
7.3943 |
0.5914 |
BP_momentum |
m
-s
|
3 |
none |
|
11 |
1.6413 |
0.0165 |
1703.5 |
7.5354 |
0.6027 |
BP_momentum |
linear |
3 |
none |
Tabelle .17: Gegenüberstellung der Modellergebnisse (Mai/Juni 1996)
|
Modell |
mape |
rmse |
|
SNNS |
1.5563 |
7.269 |
|
Komponentenmodell |
1.4662 |
7.561 |
|
Regression |
1.4651 |
7.625 |
- Juli / August
Tabelle .18: Günstigste Kombinationen exogener Zeitreihen für die Analyse (Juli/August 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Variables |
|
413 |
1.4584 |
0.0145 |
1371.9 |
6.763 |
0.7542 |
JTG_COS TG WG WR |
|
301 |
1.5033 |
0.0150 |
1377.6 |
6.777 |
0.7438 |
JTG_COS NDS_DWD TG WG |
|
415 |
1.4670 |
0.0146 |
1393.0 |
6.814 |
0.7578 |
JTG_COS TG WG WRG |
|
346 |
1.5039 |
0.0150 |
1403.5 |
6.840 |
0.7528 |
JTG_COS RLF TG WG |
|
414 |
1.4873 |
0.0148 |
1419.5 |
6.879 |
0.7519 |
JTG_COS TG WG WRSIN |
Tabelle .19: Die fünf günstigsten Netzarchitekturen für die Analyse (Juli/August 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Lernfunktion |
Skal.-Fkt. |
Hidden |
Topologie Mod. |
|
3 |
1.5851 |
0.0157 |
1642.4 |
7.3991 |
0.8384 |
BP_momentum |
linear |
10 |
vorS |
|
36 |
1.7182 |
0.0171 |
1647.8 |
7.4113 |
0.8388 |
BPM_ln_cosh |
linear |
5 |
none |
|
29 |
1.6863 |
0.0168 |
1666.5 |
7.4531 |
0.8411 |
BPM_ln_cosh |
linear |
5 |
vorS+shortC |
|
28 |
1.7662 |
0.0175 |
1708.8 |
7.5471 |
0.8486 |
BPM_ln_cosh |
linear |
3 |
vorS+shortC |
|
12 |
1.7503 |
0.0174 |
1712.9 |
7.5562 |
0.8573 |
BP_momentum |
linear |
5 |
none |
Tabelle .20: Gegenüberstellung der Modellergebnisse (Juli/August 1996)
|
Modell |
mape |
rmse |
|
Regression |
1.4584 |
6.763 |
|
Komponentenmodell |
1.4844 |
6.802 |
|
SNNS |
1.5851 |
7.399 |
- September / Oktober
Tabelle .21: Günstigste Kombinationen exogener Zeitreihen für die Analyse (September/Oktober 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Variables |
|
301 |
2.9175 |
0.0296 |
7300.8 |
15.600 |
0.8471 |
JTG_COS NDS_DWD TG WG |
|
346 |
2.8857 |
0.0293 |
7464.6 |
15.774 |
0.8566 |
JTG_COS RLF TG WG |
|
26 |
2.9490 |
0.0299 |
7519.3 |
15.832 |
0.8597 |
HAUDE JTG_COS TG WG |
|
413 |
3.1626 |
0.0320 |
7560.2 |
15.875 |
0.8620 |
JTG_COS TG WG WR |
|
415 |
3.1040 |
0.0314 |
7560.5 |
15.875 |
0.8621 |
JTG_COS TG WG WRG |
Tabelle .22: Die fünf günstigsten Netzarchitekturen für die Analyse (September/Oktober 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Lernfunktion |
Skal.-Fkt. |
Hidden |
Topologie Mod. |
|
26 |
2.3275 |
0.0233 |
4166.8 |
11.785 |
0.6400 |
BPM_ln_cosh |
linear |
10 |
vorS+shortC |
|
28 |
2.3929 |
0.0240 |
4316.8 |
11.996 |
0.6514 |
BPM_ln_cosh |
linear |
3 |
vorS+shortC |
|
23 |
2.8355 |
0.0282 |
4530.1 |
12.288 |
0.6673 |
BP_momentum |
m
-s
|
3 |
none |
|
30 |
2.4488 |
0.0246 |
4613.4 |
12.401 |
0.6734 |
BPM_ln_cosh |
linear |
3 |
vorS |
|
32 |
2.8082 |
0.0280 |
4809.2 |
12.661 |
0.6875 |
BPM_ln_cosh |
linear |
5 |
vorS |
Tabelle .23: Gegenüberstellung der Modellergebnisse (September/Oktober 1996)
|
Modell |
mape |
rmse |
|
SNNS |
2.3275 |
11.785 |
|
Komponentenmodell |
2.5517 |
13.414 |
|
Regression |
2.9175 |
15.600 |
- November / Dezember
Tabelle .24: Günstigste Kombinationen exogener Zeitreihen für die Analyse (November/Dezember 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Variables |
|
332 |
1.9653 |
0.0196 |
2535.7 |
9.194 |
0.6641 |
JTG_COS NDS_DWD WG WR |
|
652 |
1.8676 |
0.0187 |
2547.9 |
9.216 |
0.6717 |
NDS_DWD THT_FH WG WR |
|
334 |
1.9806 |
0.0197 |
2567.3 |
9.251 |
0.6680 |
JTG_COS NDS_DWD WG WRG |
|
654 |
1.8886 |
0.0189 |
2582.8 |
9.279 |
0.6761 |
NDS_DWD THT_FH WG WRG |
|
333 |
1.9918 |
0.0199 |
2588.7 |
9.289 |
0.6721 |
JTG_COS NDS_DWD WG WRSIN |
Tabelle .25: Die fünf günstigsten Netzarchitekturen für die Analyse (November/Dezember 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Lernfunktion |
Skal.-Fkt. |
Hidden |
Topologie Mod. |
|
25 |
1.8194 |
0.0181 |
2227.6 |
8.617 |
0.6267 |
BPM_ln_cosh |
linear |
7 |
none |
|
36 |
1.9211 |
0.0191 |
2375.9 |
8.899 |
0.6458 |
BPM_ln_cosh |
linear |
5 |
none |
|
2 |
1.9271 |
0.0192 |
2477.6 |
9.088 |
0.6540 |
BP_momentum |
linear |
10 |
vorS+shortC |
|
33 |
1.9985 |
0.0198 |
2497.1 |
9.123 |
0.6605 |
BPM_ln_cosh |
linear |
10 |
none |
|
35 |
1.9942 |
0.0198 |
2573.0 |
9.261 |
0.6698 |
BPM_ln_cosh |
linear |
3 |
none |
Tabelle .26: Gegenüberstellung der Modellergebnisse (November/Dezember 1996)
|
Modell |
mape |
rmse |
|
Komponentenmodell |
1.8923 |
7.999 |
|
SNNS |
1.8194 |
8.617 |
|
Regression |
1.9653 |
9.194 |
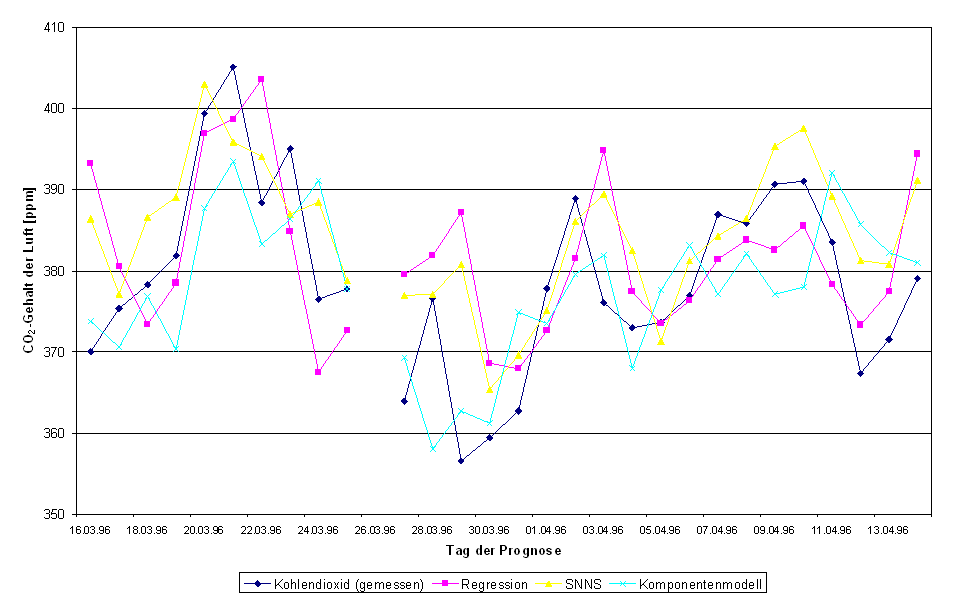
Bild .1: Vergleich der Prognosegüte der drei Verfahren (Zeitraum März / April 1996)
- Januar / Februar
Die fünf günstigsten Kombinationen exogener Zeitreihen für den Prognoseezeitraum können Tabelle 4.9 entnommen werden.
Tabelle .27: Günstigste Kombinationen exogener Zeitreihen für die Prognose (Januar/Februar 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Exogene Variablen |
|
710 |
2.2844 |
0.0228 |
5690.8 |
13.773 |
0.8151 |
RLF TMP_DWD TMP_FH WG |
|
95 |
2.3152 |
0.0231 |
5722.3 |
13.811 |
0.8174 |
HAUDE NDS_DWD TMP_FH THT_FH |
|
884 |
2.3021 |
0.0230 |
5727.3 |
13.817 |
0.8177 |
TMP_DWD TMP_FH THT_FH WRSIN |
|
709 |
2.3223 |
0.0232 |
5735.2 |
13.827 |
0.8183 |
RLF TMP_DWD TMP_FH THT_FH |
|
886 |
2.3112 |
0.0231 |
5735.2 |
13.827 |
0.8183 |
TMP_DWD TMP_FH THT_FH WRGSIN |
Tabelle .28: Die fünf günstigsten Netzarchitekturen für die Prognose (Januar/Februar 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Lernfunktion |
Skal.-Fkt. |
Hidden |
Topologie Mod. |
|
7 |
2.3158 |
0.0231 |
5298.4 |
13.290 |
0.7865 |
BP_momentum |
linear |
7 |
vorS+shortC |
|
25 |
2.3077 |
0.0231 |
5303.8 |
13.296 |
0.7869 |
BPM_ln_cosh |
linear |
7 |
none |
|
31 |
2.3101 |
0.0231 |
5317.1 |
13.313 |
0.7879 |
BPM_ln_cosh |
linear |
7 |
vorS+shortC |
|
29 |
2.2803 |
0.0228 |
5346 |
13.349 |
0.790 |
BPM_ln_cosh |
linear |
5 |
vorS+shortC |
|
30 |
2.2198 |
0.0223 |
5378 |
13.389 |
0.7924 |
BPM_ln_cosh |
linear |
3 |
vorS |
Tabelle .29: Gegenüberstellung der Modellergebnisse (Januar/Februar 1996)
|
Modell |
mape |
rmse |
|
SNNS |
2.3158 |
13.290 |
|
Regression |
2.2844 |
13.773 |
|
Komponentenmodell |
2.2842 |
13.782 |
- März / April
Tabelle .30: Günstigste Kombinationen exogener Zeitreihen für die Prognose (März/April 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Exogene Variablen |
|
682 |
2.0769 |
0.0209 |
2838.4 |
10.068 |
0.8934 |
RLF TG TMP_FH WG |
|
693 |
2.0592 |
0.0207 |
2857.3 |
10.102 |
0.8963 |
RLF TG THT_FH WG |
|
832 |
2.0672 |
0.0208 |
2875.8 |
10.134 |
0.8992 |
TG TMP_FH WG WRSIN |
|
688 |
2.0829 |
0.0210 |
2886.9 |
10.154 |
0.9010 |
RLF TG THT_DWD WG |
|
675 |
2.0751 |
0.0209 |
2887.6 |
10.155 |
0.9011 |
RLF TG TMP_DWD WG |
Tabelle .31: Die fünf günstigsten Netzarchitekturen für die Prognose (März/April 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Lernfunktion |
Skal.-Fkt. |
Hidden |
Topologie Mod. |
|
45 |
1.9260 |
0.0192 |
2441.1 |
9.3372 |
0.8285 |
BPM_ln_cosh |
m
-s
|
10 |
none |
|
12 |
1.9274 |
0.0192 |
2452.1 |
9.3581 |
0.8304 |
BP_momentum |
linear |
5 |
none |
|
27 |
1.8731 |
0.0187 |
2479.8 |
9.4109 |
0.8350 |
BPM_ln_cosh |
linear |
10 |
vorS |
|
48 |
1.8908 |
0.0190 |
2491.8 |
9.4335 |
0.8371 |
BPM_ln_cosh |
m
-s
|
5 |
none |
|
25 |
1.9263 |
0.0192 |
2540.1 |
9.5247 |
0.8451 |
BPM_ln_cosh |
linear |
7 |
none |
Tabelle .32: Gegenüberstellung der Modellergebnisse (März/April 1996)
|
Modell |
mape |
rmse |
|
SNNS |
1.9260 |
9.337 |
|
Regression |
2.0769 |
10.068 |
|
Komponentenmodell |
2.0911 |
10.439 |
- Mai / Juni
Tabelle .33: Günstigste Kombinationen exogener Zeitreihen für die Prognose (Mai/Juni 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Exogene Variablen |
|
205 |
1.7549 |
0.0178 |
3200.4 |
10.329 |
0.8261 |
HAUDE TMP_DWD TMP_FH WG |
|
167 |
1.7612 |
0.0178 |
3269.7 |
10.44 |
0.8350 |
HAUDE TG TMP_DWD TMP_FH |
|
177 |
1.7810 |
0.018 |
3310.9 |
10.505 |
0.8402 |
HAUDE TG TMP_FH WG |
|
203 |
1.7891 |
0.0181 |
3315.7 |
10.513 |
0.8408 |
HAUDE TMP_DWD TMP_FH THT_DWD |
|
232 |
1.8066 |
0.0183 |
3324.8 |
10.527 |
0.8420 |
HAUDE TMP_FH THT_DWD WG |
Tabelle .34: Die fünf günstigsten Netzarchitekturen für die Prognose (Mai/Juni 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Lernfunktion |
Skal.-Fkt. |
Hidden |
Topologie Mod. |
|
11 |
1.6998 |
0.0172 |
3061.3 |
10.102 |
0.8079 |
BP_momentum |
linear |
3 |
none |
|
33 |
1.7482 |
0.0177 |
3083.9 |
10.139 |
0.8109 |
BPM_ln_cosh |
linear |
10 |
none |
|
25 |
1.7114 |
0.0174 |
3088.1 |
10.146 |
0.8115 |
BPM_ln_cosh |
linear |
7 |
none |
|
32 |
1.7664 |
0.0178 |
3090.7 |
10.150 |
0.8118 |
BPM_ln_cosh |
linear |
5 |
vorS |
|
12 |
1.7423 |
0.0177 |
3128.3 |
10.212 |
0.8167 |
BP_momentum |
linear |
5 |
none |
Tabelle .35: Gegenüberstellung der Modellergebnisse (Mai/Juni 1996)
|
Modell |
mape |
rmse |
|
Komponentenmodell |
1.7082 |
10.098 |
|
SNNS |
1.6998 |
10.102 |
|
Regression |
1.7549 |
10.329 |
- Juli / August
Tabelle .36: Günstigste Kombinationen exogener Zeitreihen für die Prognose (Juli/August 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Variables |
|
205 |
1.5732 |
0.0158 |
1540.3 |
7.2880 |
0.826 |
HAUDE TMP_DWD TMP_FH WG |
|
794 |
1.6056 |
0.0161 |
1545.9 |
7.3012 |
0.8275 |
TG TMP_DWD TMP_FH WG |
|
167 |
1.5497 |
0.0155 |
1546.3 |
7.3022 |
0.8276 |
HAUDE TG TMP_DWD TMP_FH |
|
793 |
1.5550 |
0.0156 |
1548.2 |
7.3066 |
0.8281 |
TG TMP_DWD TMP_FH THT_FH |
|
797 |
1.5830 |
0.0159 |
1559.2 |
7.3324 |
0.8311 |
TG TMP_DWD TMP_FH WRG |
Tabelle .37: Die fünf günstigsten Netzarchitekturen für die Prognose (Juli/August 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Lernfunktion |
Skal.-Fkt. |
Hidden |
Topologie Mod. |
|
9 |
1.5587 |
0.0156 |
1460.5 |
7.0965 |
0.8043 |
BP_momentum |
linear |
10 |
none |
|
33 |
1.5013 |
0.0151 |
1528.5 |
7.2600 |
0.8228 |
BPM_ln_cosh |
linear |
10 |
none |
|
30 |
1.5815 |
0.0158 |
1538.5 |
7.2837 |
0.8255 |
BPM_ln_cosh |
linear |
3 |
vorS |
|
35 |
1.5177 |
0.0153 |
1596.8 |
7.4203 |
0.8410 |
BPM_ln_cosh |
linear |
3 |
none |
|
27 |
1.5693 |
0.0158 |
1602.1 |
7.4328 |
0.8424 |
BPM_ln_cosh |
linear |
10 |
vorS |
Tabelle .38: Gegenüberstellung der Modellergebnisse (Juli/August 1996)
|
Modell |
mape |
rmse |
|
SNNS |
1.5587 |
7.0965 |
|
Komponentenmodell |
1.5665 |
7.2435 |
|
Regression |
1.5732 |
7.2880 |
- September / Oktober
Tabelle .39: Günstigste Kombinationen exogener Zeitreihen für die Prognose (September/Oktober 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Variables |
|
794 |
3.0393 |
0.0305 |
7320.1 |
15.621 |
0.8482 |
TG TMP_DWD TMP_FH WG |
|
826 |
3.1179 |
0.0313 |
7432.3 |
15.74 |
0.8547 |
TG TMP_FH THT_FH WG |
|
798 |
3.2475 |
0.0326 |
7455.9 |
15.765 |
0.8561 |
TG TMP_DWD TMP_FH WRGSIN |
|
895 |
3.249 |
0.0328 |
7495.1 |
15.806 |
0.8583 |
TMP_DWD TMP_FH WRSIN WRGSIN |
|
890 |
3.1397 |
0.0317 |
7497.3 |
15.809 |
0.8584 |
TMP_DWD TMP_FH WG WRGSIN |
Tabelle .40: Die fünf günstigsten Netzarchitekturen für die Prognose (September/Oktober 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Lernfunktion |
Skal.-Fkt. |
Hidden |
Topologie Mod. |
|
11 |
2.9996 |
0.0298 |
5356.8 |
13.363 |
0.7256 |
BP_momentum |
linear |
3 |
none |
|
3 |
3.0307 |
0.0303 |
6108.3 |
14.269 |
0.7749 |
BP_momentum |
linear |
10 |
vorS |
|
1 |
2.9082 |
0.0292 |
6529.6 |
14.753 |
0.8011 |
BP_momentum |
linear |
7 |
none |
|
9 |
3.0955 |
0.0308 |
6641.4 |
14.879 |
0.808 |
BP_momentum |
linear |
10 |
none |
|
25 |
2.9767 |
0.0299 |
6684.9 |
14.927 |
0.8106 |
BPM_ln_cosh |
linear |
7 |
none |
Tabelle .41: Gegenüberstellung der Modellergebnisse (September/Oktober 1996)
|
Modell |
mape |
rmse |
|
SNNS |
2.9996 |
13.363 |
|
Komponentenmodell |
2.8973 |
14.012 |
|
Regression |
3.0393 |
15.621 |
- November / Dezember
Tabelle .42: Günstigste Kombinationen exogener Zeitreihen für die Prognose (November/Dezember 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Variables |
|
348 |
2.4604 |
0.0245 |
4424.8 |
12.352 |
0.8884 |
JTG_COS RLF TG WRSIN |
|
350 |
2.458 |
0.0245 |
4426.7 |
12.355 |
0.8886 |
JTG_COS RLF TG WRGSIN |
|
386 |
2.4769 |
0.0248 |
4435.8 |
12.368 |
0.8895 |
JTG_COS RLF WRG WRGSIN |
|
66 |
2.4711 |
0.0247 |
4444.0 |
12.379 |
0.8903 |
HAUDE JTG_COS WRG WRGSIN |
|
422 |
2.4642 |
0.0245 |
4446.0 |
12.382 |
0.8905 |
JTG_COS TG WRG WRGSIN |
Tabelle .43: Die fünf günstigsten Netzarchitekturen für die Prognose (November/Dezember 1996)
|
Run |
mape |
mre |
sres |
rmse |
theil |
Lernfunktion |
Skal.-Fkt. |
Hidden |
Topologie Mod. |
|
45 |
2.5803 |
0.0256 |
4565.1 |
12.547 |
0.9024 |
BPM_ln_cosh |
m
-s
|
10 |
none |
|
37 |
2.5845 |
0.0257 |
4583.5 |
12.572 |
0.9042 |
BPM_ln_cosh |
m
-s
|
7 |
none |
|
48 |
2.597 |
0.0258 |
4664.1 |
12.682 |
0.9121 |
BPM_ln_cosh |
m
-s
|
5 |
none |
|
35 |
2.4982 |
0.0248 |
4672.1 |
12.693 |
0.9129 |
BPM_ln_cosh |
linear |
3 |
none |
|
28 |
2.4989 |
0.0248 |
4680.7 |
12.705 |
0.9137 |
BPM_ln_cosh |
linear |
3 |
vorS+shortC |
Tabelle .44: Gegenüberstellung der Modellergebnisse (November/Dezember 1996)
|
Modell |
mape |
rmse |
|
Komponentenmodell |
2.3903 |
11.986 |
|
Regression |
2.4604 |
12.352 |
|
SNNS |
2.5803 |
12.547 |
ARIMA-Modellierung
Aufgrund ihres autoregressiven und des Moving-Average-Prozesses kann die ARIMA-Modellierung nur für Datenreihen ohne Fehlwerte verwendet werden. Selbst einzelne "missing values", die bei naturwissenschaftlichen Datenreihen oftmals zu finden sind, schließen eine zuverlässige und aussagekräftige ARIMA-Modellierung aus. Aus diesem Grund wird der Vergleich dieser Art von Modellen mit den Neuronalen Netzen auf den längsten, vollständigen Abschnitten der CO2-Zeitreihe durchgeführt. Dies ist zum einen der Zeitraum vom 19.11.94 bis zum 10.12.95 mit 387 Tagen und zum anderen die 178 Tage zwischen dem 24.05.94 und dem 17.11.95. Als Vergleich wird jeweils eine Prognose durchgeführt, die die letzten 30 Tage der Zeiträume umfaßt.
Für die multivariaten Modelle SNNS und Regression müssen noch die Inputzeitreihen festgelegt werden. Das neuronale Netz erhält als Input CO2 (Vortageswert), WG, TMP_DWD, NDS_DWD und WR_SIN. Die Regression erhält ebenfalls den CO2-Vortageswert und analog zu dem in Kapitel 4.2.1 vorgestellten Vorgehen vier von 11 möglichen exogenen Zeitreihen.
Zeitraum 1 (19.11.94 bis 10.12.95, 387 Tage)
Die Autokorrelationen und partiellen Autokorrelationen identifizieren die CO2-Zeitreihe auf diesem Abschnitt als einen ARIMA[1,0,0]-Prozeß. In Abbildung 4.7 werden Autokorrelation und partielle Autokorrelation des undifferenzierten Zeitreihenabschnitts gezeigt.
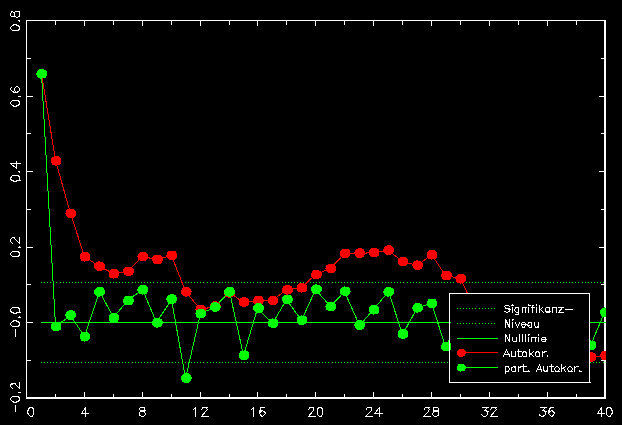
Abbildung .7: (Partielle) Autokorrelationen zur undifferenzierten CO2-Zeitreihe (19.11.94 bis 10.12.95)
Als günstigste Netzarchitektur auf dem untersuchten Intervall erwies sich ein FF-MLP mit BPM_ln_cosh als Lernfunktion, linearer Skalierung der Zeitreihen, 7 Neuronen in der Hiddenschicht und ohne Vorschicht oder Shortcuts. Auf diesem Abschnitt sind die multivariaten Verfahren (SNNS, Regression) dem ARIMA-Modell deutlich überlegen. Eine Gegenüberstellung der Modellfehler findet sich in Tabelle 4.45.
Tabelle .45: Vergleich der Prognosefehler der einzelnen Verfahren
|
Verfahren |
MAPE |
RMSE |
|
SNNS |
2.6502 |
13.4593 |
|
Regression |
2.7535 |
14.4789 |
|
ARIMA[1,0,0] |
3.0123 |
15.9489 |
Abbildung 4.8 zeigt die CO2-Zeitreihe und die Modellreihen im Vergleich. Es ist deutlich zu erkennen, daß die Modellzeitreihen dem wahren Wert "hinterherlaufen".
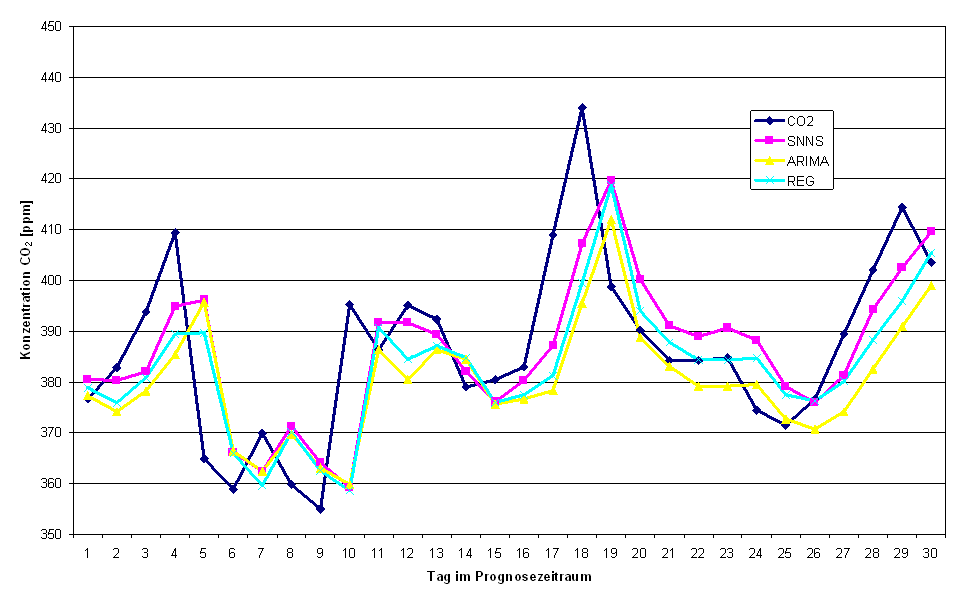
Abbildung .8: Vergleich der Verfahren im dem Prognosezeitraum 1 (19.11.94 bis 10.12.95)
Zeitraum 2 (24.05.94 bis 17.11.95, 178 Tage)
Auch dieser Abschnitt der CO2-Zeitreihe wird mittels der Autokorrelationen und partiellen Autokorrelationen als ein ARIMA[1,0,0]-Prozeß identifiziert. Abbildung 4.9 zeigt die Autokorrelation und partielle Autokorrelation des undifferenzierten Zeitreihenabschnitts.
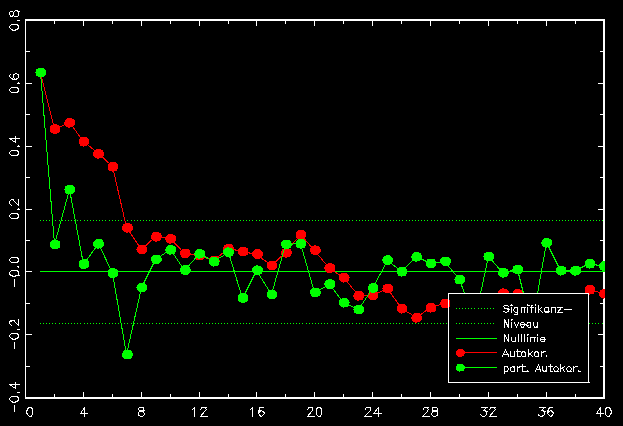
Abbildung .9: (Partielle) Autokorrelationen zur undifferenzierten CO2-Zeitreihe (24.05.94 bis 17.11.94)
Wieder setzen sich das ARIMA-Modell und die SNNS-Prognose deutlich gegenüber der Regression ab. Diesmal allerdings liefert das ARIMA-Verfahren eine bessere Prognoseleistung als das beste Neuronale Netz. Eine Gegenüberstellung der Modellfehler findet sich in Tabelle 4.46.
Tabelle .46: Vergleich der Prognosefehler der einzelnen Verfahren
|
Verfahren |
MAPE |
RMSE |
|
ARIMA[1,0,0] |
2.3490 |
10.3926 |
|
SNNS |
2.3632 |
10.6344 |
|
Regression |
2.7213 |
12.0172 |
Abbildung 4.10 zeigt die CO2-Zeitreihe und die Modellreihen im Vergleich.
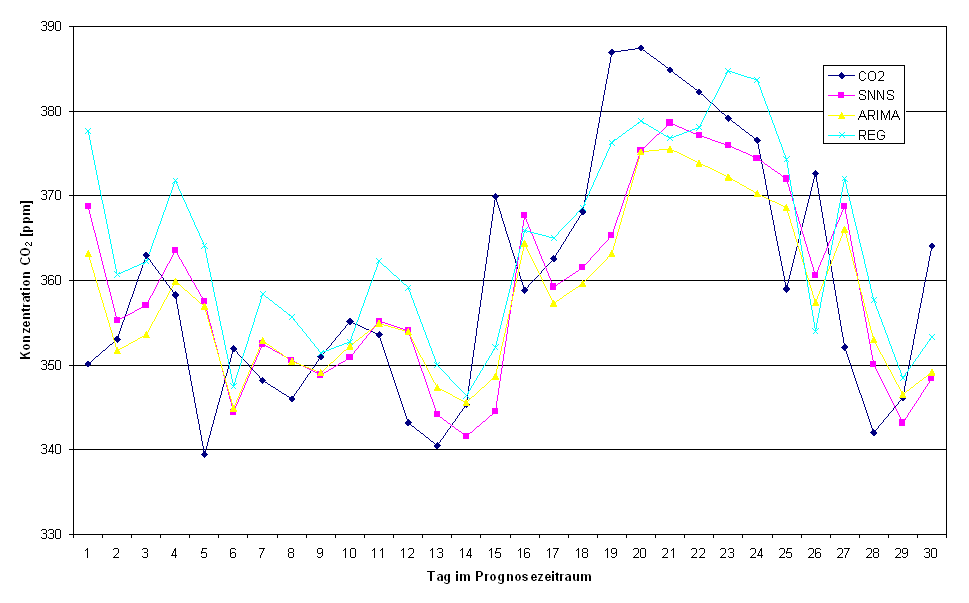
Abbildung .10: Vergleich der Verfahren in Prognosezeitraum 2 (24.05.94 bis 17.11.94)
Verfahren zur Auswahl exogener Zeitreihen für Neuronale Netze
Pruning
Das Pruning-Verfahren wurde in Kapitel 3.2.5 vorgestellt. Um eine weitgehende Optimierung der Netzarchitektur zu erreichen, wurde SNNS um die Möglichkeit erweitert, bis zu drei verschiedene Pruning-Verfahren nacheinander anzuwenden. Im folgenden werden die einzelnen Schritte beim Ablauf dargestellt. Dazu wird von einem recht umfangreichen Netz mit allen 22 Inputs und 20 Neuronen in der verborgenen Schicht ausgegangen. Im ersten Schritt werden nun die Gewichte bzw. Links geprunt, um die Zahl der freien Variablen einzuschränken. Interessant wird es dann in den nächsten beiden Schritten, wenn erst die Hidden-Neuronen und dann die Inputs geprunt werden. Abbildung 4.11 zeigt die Anzahl der Neuronen in den beiden Schichten im Verlauf des Prunings.
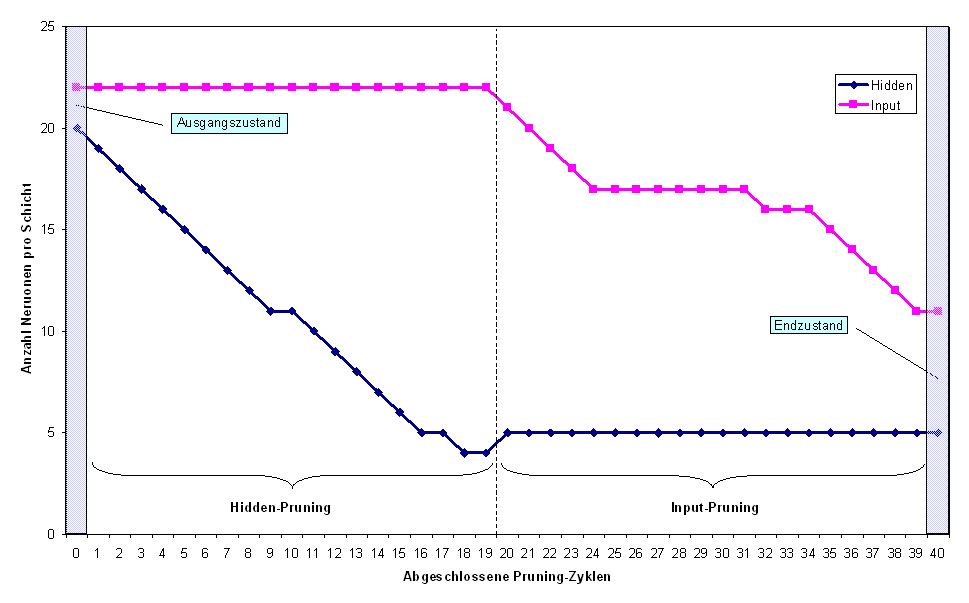
Abbildung .11: Anzahl der Neuronen in Hidden- und Input-Schicht im Verlauf des Verfahrens
Die Anzahl der Neuronen in der verborgenen Schicht reduziert sich zunächst von 20 auf vier reduziert, den besten Testfehler liefert jedoch das Netz mit fünf Hidden-Neuronen, so daß nach Ende des Hidden-Prunings (nach Zyklus 19) wieder mit fünf Neuronen in der verborgenen Schicht gearbeitet wird. Eine Stagnation der Neuronenanzahl, wie sie für die Zyklen 26 bis 31 für die Input-Neuronen beobachtet werden, rührt daher, daß das Entfernen eines Neurons das Netz auch mit Nachtraining nicht verbessert.
Für die Auswahl der zu entfernenden Input-Neuronen wird die "Wichtigkeit" jedes Neurons, also der Beitrag zum Netzfehler, berechnet. Entfernt wird immer das jeweils unwichtigste Neuron. Tabelle 4.47 zeigt eine Übersicht über die Reihenfolge beim Input-Pruning.
Tabelle .47: Ablauf des Input-Prunings
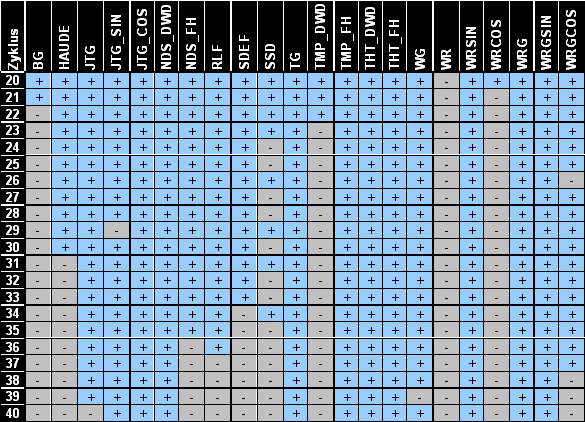
Die endgültige Netzkonfiguration ist ein Netz mit 11 Inputs und fünf Neuronen in der verborgenen Schicht.
Auswahl nach Sensitivität
Zur Bewertung des Verfahrens wurde eine Analyse auf den letzten 50 Tagen der zur Verfügung stehenden Daten durchgeführt. Ausgehend von 22 exogenen Zeitreihen wurde als Zielgröße 4 Zeitreihen festgelegt und der Fehlerverlauf des Verfahrens betrachtet. Abbildung 4.12 zeigt eine graphische Darstellung des Fehlerverlaufs. Durch die Fehlerwerte für 22 bis fünf Inputzeitreihen wurde eine Trendlinie mit Hilfe der Methode der kleinsten Quadrate gelegt. Die zugrundeliegende Topologie ist ein dreischichtiges FF-MLP mit der Lernfunktion BPM_ln_cosh, ohne Vorschicht, mit Shortcuts von der Input- zur Outputschicht und mit logistischer Aktivierungsfunktion. Alle anderen Einstellungen wurden aus Abschnitt 4.2.5 übernommen.
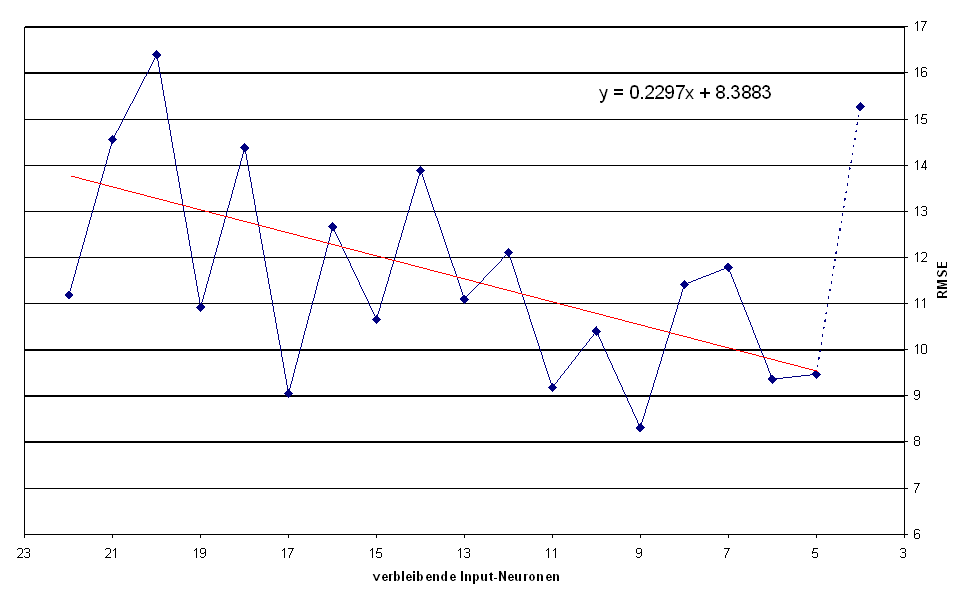
Abbildung .12: Fehlerverlauf des Sensitivitätsmodells zur Auswahl geeigneter Inputparameter
Die in den verschiedenen Verfahrensschritten entfernten Input-Neuronen mit ihren Sensitivitäten werden zusammen mir dem jeweiligen Netzfehler in Tabelle 4.48 aufgeführt.
Tabelle .48: Übersicht über den Ablauf des Sensitivitätsmodells
|
Verfahrens-
schritt |
Inputs
davor |
RMSE
davor |
Entferntes
Inputneuron |
Sensitivität
des Neurons |
Inputs
danach |
RMSE
danach |
|
1 |
22 |
11.185 |
BG |
0.000521 |
21 |
14.555 |
|
2 |
21 |
14.555 |
WRCOS |
0.000233 |
20 |
16.398 |
|
3 |
20 |
16.398 |
WRG |
0.000339 |
19 |
10.924 |
|
4 |
19 |
10.924 |
JTG |
0.004377 |
18 |
14.378 |
|
5 |
18 |
14.378 |
THT_FH |
0.003276 |
17 |
9.047 |
|
6 |
17 |
9.047 |
TMP_FH |
0.000532 |
16 |
12.662 |
|
7 |
16 |
12.662 |
HAUDE |
0.008275 |
15 |
10.655 |
|
8 |
15 |
10.665 |
RLF |
0.006033 |
14 |
13.889 |
|
9 |
14 |
13.889 |
WR |
0.002944 |
13 |
11.092 |
|
10 |
13 |
11.092 |
JTG_SIN |
0.000367 |
12 |
12.105 |
|
11 |
12 |
12.105 |
WRGCOS |
0.001470 |
11 |
9.181 |
|
12 |
11 |
9.181 |
NDS_FH |
0.029431 |
10 |
10.403 |
|
13 |
10 |
10.403 |
SDEF |
0.007034 |
9 |
8.311 |
|
14 |
9 |
8.311 |
SSD |
0.017033 |
8 |
11.412 |
|
15 |
8 |
11.412 |
THT_DWD |
0.034345 |
7 |
11.791 |
|
16 |
7 |
11.791 |
TMP_DWD |
0.001584 |
6 |
9.361 |
|
17 |
6 |
9.361 |
TG |
0.022068 |
5 |
9.466 |
|
18 |
5 |
9.466 |
JTG_COS |
0.100004 |
4 |
15.264 |
Die günstigste Konfiguration ergab sich nach 13 Verfahrensschritten, als noch neun Input-Neuronen übrig waren. Die Sensitivitäten dieser Topologie finden sich in Tabelle 4.49.
Tabelle .49: Die günstigsten Inputparameter (nach Sensitivitätsmodell) mit Sensitivitäten
|
Parameter |
Sensitivität |
|
NDS_DWD |
0.0838 |
|
TMP_DWD |
0.1163 |
|
THT_DWD |
0.1205 |
|
WG |
0.1192 |
|
SSD |
0.0170 |
|
WRSIN |
0.1193 |
|
WRGSIN |
0.1297 |
|
JTG_COS |
0.1052 |
|
TG |
0.0306 |
Vergleich der Verfahren
Beide Verfahren wurden im Rahmen eine Analyse auf den letzten 50 Tagen des Jahres 1996 getestet und miteinander verglichen. Eine Auswertung der Netzfehler der endgültigen Netze ist in Tabelle 4.50 gegeben.
Tabelle .50: Vergleich der Verfahren zur Verbesserung der Netztopologie
|
Verfahren |
mape |
mre |
sres |
rmse |
theil |
|
Sensitivitätsmodell |
1.6859 |
0.0169 |
3108.3 |
8.311 |
0.5511 |
|
Pruning-Verfahren |
2.8692 |
0.0282 |
7445.6 |
12.863 |
0.8483 |
Auf dem betrachteten Intervall zeigt die Netzarchitektur des Sensitivitätsmodells einen deutlich geringeren Netzfehler als die des Pruning-Verfahrens.