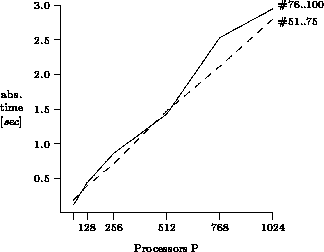
Figure 4: Absolute time of first phase
Figure 4: Absolute time of first phase
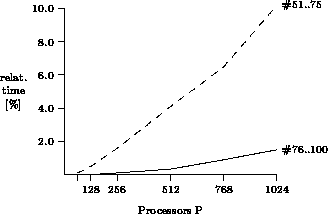
Figure 5: Time of first phase relative to total search time
In the first phase, all processors perform a synchronous
iterative-deepening search on the first few tree levels,
storing all nodes of the last search frontier
until there are at least 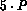 nodes in each processor's local node array.
This gives a sufficient number of work packets
while not overflowing the memory resources.
nodes in each processor's local node array.
This gives a sufficient number of work packets
while not overflowing the memory resources.
For the larger systems, more nodes must be generated to give every processor a sufficient amount of `own' nodes to work on. Hence, the CPU time spent in the first phase increases linearly with the system size, as shown in Figure 4. This additional node generation overhead does not reduce the overall efficiency of AIDA* in the large problems #76..100 too much. As shown in Figure 5, less than 1.5% of the total search time is spent in the first phase. Only the small problems #51..75 require up to 10% for the initial work-load distribution. This is just another manifestation of Amdahl's Law. The scalability of AIDA* can be improved by reducing the size of the first phase or by expanding different subtrees on the parallel processors in a divide-and-conquer approach.
Note, that in the second phase, every processor starts node expansion on its own subtrees, thereby fully exploiting the parallel processing power.