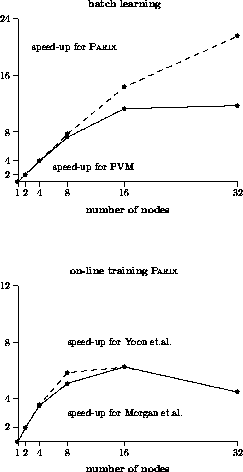
Figure 4: Speed-ups for GC/PP with PowerPC CPUs
For enhancement the back-propagation algorithm has been parallelized in different manners: First the training set can be partitioned for the batch learning implementation. The neural network is duplicated on every processor of the parallel machine, and each processor works with a subset of the training set. After each epoch the calculated weight corrections are broadcasted and merged.
The second approach is a parallel calculation of the matrix products that are used in the learning algorithm. The neurons on each layer are partitioned into p disjoint sets and each set is mapped on one of the p processors. After the calculation of the new activations of the neurons in one layer they are broadcasted. We have implemented this on-line training in two variants: For the first parallelization of Morgan et al.[1] one matrix product is not determined on one processor, but it is calculated while the subsums are sent around on a processor cycle. The second method of Yoon et al.[5] tries to reduce the communication time. This leads to an overhead in both storage and number of computational operations.
All parallel algorithms are implemented on PARSYTEC multiprocessor systems based on Transputers and PowerPC processors using the message passing environments PARIX and PVM. The measurements took place on a GC/PP at the University of Paderborn, Germany. The speed-ups for parallel training are shown in figure 4.
One can see that the parallelization of the batch learning scales very good. Concerning the on-line training the parallelization of Yoon outperforms Morgan's parallelization a little bit. For 32 processors these parallelizations do not scale anymore because of their enormous communication demands.