Results on Floorplan Optimization
Next: Scalability Analysis
Up: Empirical Results
Previous: Effect of Different
We implemented a DFS-Branch-and-Bound algorithm with our fixed-packet
work-load distribution scheme for the floorplan optimization problem.
We tested our algorithm with an instance consisting of 25 blocks
and five different implementations per block, which spawns a search
tree with 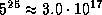 nodes.
In the initial distribution phase, the first levels of the tree are
expanded to get
nodes.
In the initial distribution phase, the first levels of the tree are
expanded to get 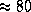 frontier nodes for each processor.
The proportion of the first phase to the parallel execution time ranges
from 0.2% (
frontier nodes for each processor.
The proportion of the first phase to the parallel execution time ranges
from 0.2% (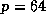 ) to 4.6% (
) to 4.6% (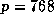 ).
As in the 15- and 19-puzzle, the first phase gives a good
initial work distribution, which keeps the processors working on their local
nodes for more than 90% of the total execution time.
Note, that in this time there is no communication for load balancing required,
only newly computed bound values have to be broadcasted.
Parallelism is fully exploited since all processors execute
the sequential search algorithm on their local nodes.
This results in a high work-rate even for larger systems as shown in
Table 2.
).
As in the 15- and 19-puzzle, the first phase gives a good
initial work distribution, which keeps the processors working on their local
nodes for more than 90% of the total execution time.
Note, that in this time there is no communication for load balancing required,
only newly computed bound values have to be broadcasted.
Parallelism is fully exploited since all processors execute
the sequential search algorithm on their local nodes.
This results in a high work-rate even for larger systems as shown in
Table 2.

Table 2: Average work-rate (nodes per sec.)
At first sight, the exhaustive search of our
fixed-packet DFBB might seem less efficient, because
the single processors would terminate at different times
due to the fixed work-packet sizes.
But in practice, we found that due to the better bounds
the subtrees are getting smaller to the
end of the search, so that the termination times are very close to each other.
Volker Schnecke
Fri Dec 16 11:20:32 MET 1994