Stack-Splitting DFS
Next: Fixed-Packet DFS
Up: Two Approaches to
Previous: Two Approaches to
In the parallel stack-splitting DFSdescribed by
Kumar and Rao [12][7]
each processor works on its own local stack that keeps track of the
untried alternatives.
When the local stack is empty, a processor issues a work-request
to another processor for an unsearched subtree.
The donor then splits its stack and sends a part of its own
work to the requester.
Initially, all work is given to one processor, 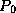 ,
which performs DFS on the root node.
The other processors start with an empty stack,
immediately asking for work.
When has generated enough nodes,
it splits its stack, donating subtrees to the requesting processors,
which likewise split their stacks on demand.
,
which performs DFS on the root node.
The other processors start with an empty stack,
immediately asking for work.
When has generated enough nodes,
it splits its stack, donating subtrees to the requesting processors,
which likewise split their stacks on demand.
This scheme works for simple DFS as well as for iterative DFS.
In the latter case, the algorithm is named PIDA*,
for Parallel IDA* [12].
PIDA* starts a new iteration with the an increased cost-bound
when all processors have finished their current iteration without
finding a goal node.
The end of an iteration is determined by a barrier synchronization
algorithm,
e.g., Dijkstra's termination detection algorithm [3].
The performance results in the literature
[15][13][7]
and our own experiments indicate that stack-splitting works only
on moderately parallel systems with 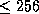 processors
and a small communication diameter.
It does not seem to scale up for larger system sizes
because of high communication overheads and inherent work load imbalances.
Two major bottlenecks make stack-splitting impractical
for massively parallel systems:
processors
and a small communication diameter.
It does not seem to scale up for larger system sizes
because of high communication overheads and inherent work load imbalances.
Two major bottlenecks make stack-splitting impractical
for massively parallel systems:
- on networks with a large communication diameter
it takes a long time to equally distribute the initial work-load
among the processors
- recursive stack-splitting generates work packets of dissimilar sizes,
resulting in vastly different (and unpredictable)
processing times per packet.
Moreover, the stack-splitting method requires implementation of explicit stack
handling routines, which is more error-prone and less efficient
than the compiler-generated recursive program code [15].
Next: Fixed-Packet DFS
Up: Two Approaches to
Previous: Two Approaches to
Volker Schnecke
Fri Dec 16 11:20:32 MET 1994