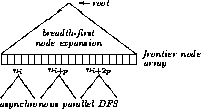
Figure 1: Fixed-Packet DFS Program Architecture
Figure 1: Fixed-Packet DFS Program Architecture
Our second scheme, named fixed-packet DFS, has the two working phases shown in Figure 1:
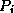 starts expanding its subtrees
starts expanding its subtrees
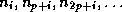 in DFBB fashion
in DFBB fashion
In practice, little work-load balancing is required,
because the initial distribution phase (taking only a few seconds)
keeps the processors busy for more than 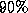 of the time
without any loadbalancing.
of the time
without any loadbalancing.
Our fixed-packet DFS scheme ships fine-grained work packets that are not further splitted. Hence, existing sequential DFS applications can be linked to our communication code to build a highly parallel DFS program without modifying the code.
Fixed-packet DFS is especially effective in combination with iterative-deepening search [16]. We named it AIDA* for asynchronous parallel IDA*. AIDA* expands the frontier node subtrees in an iterative-deepening manner until a solution is found.
Unlike PIDA*, AIDA* does not perform a hard barrier synchronization between the iterations. When a processor could not get further work, it is allowed to proceed asynchronously with the next iteration, first expanding its own local frontier nodes to the next larger cost-bound. On one hand, this reduces processor idle times, but on the other hand, the search cannot be stopped right after a first solution has been found. Instead, the processors working on earlier iterations must continue their search to check for better solutions.
Note, that in AIDA* the work packets change ownership when being sent to another processor. This has the effect of a self-improving global work-load balancing because subtrees tend to grow at the same rate when being expanded to the next larger search bound. Lightly loaded processors that asked for work in the last iteration will be better utilized in the next. More important, the communication overhead decreases with increasing search time [16].