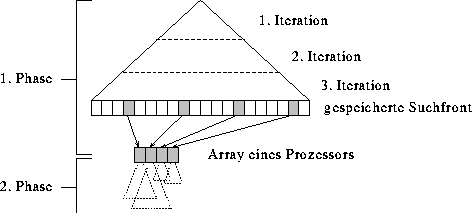
Figure 2: Die zwei Phasen des Algorithmus AIDA*
Figure 2: Die zwei Phasen des Algorithmus AIDA*
Der Algorithmus AIDA* (Asynchronous parallel IDA*) verwendet ein zweiphasiges Lastverteilungsverfahren, welches nicht auf einem Stack-Splitting, sondern auf einem Search-Frontier-Splitting (Aufteilen der Suchfront anstelle von Aufteilen des Stacks) basiert. Dabei wird der Baum bis zu einer bestimmten Tiefe expandiert, wobei die sich dabei ergebende Suchfront unter den Prozessoren des Systems aufgeteilt wird.
In der Initialverteilungsphase beginnen alle Prozessoren redundant damit, die ersten
Iterationen auszuführen,
wobei die Knoten der jeweiligen Suchfront in einem Array in jedem Prozessor
gespeichert werden.
Hat diese Suchfront eine bestimmte Größe erreicht, so wird sie gleichmäßig
unter den Prozessoren aufgeteilt.
Ein Prozessor 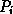 erhält dabei die Knoten
erhält dabei die Knoten 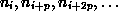 , so
daßdie Suchfront breit über das System verteilt wird.
Dieses ist ein großer Vorteil gegenüber den Stack-Splitting Verfahren, wo sich
die Suchfront durch das System ,,schiebt``, so daßim Baum benachbarte Knoten
auch im System nah beieinander liegen.
Ein weiterer Vorteil dieser Initialverteilungsstrategie ist, daßsie - bis auf das
Verbreiten der Wurzel - ohne jede Kommunikation oder Synchronisation erfolgt.
, so
daßdie Suchfront breit über das System verteilt wird.
Dieses ist ein großer Vorteil gegenüber den Stack-Splitting Verfahren, wo sich
die Suchfront durch das System ,,schiebt``, so daßim Baum benachbarte Knoten
auch im System nah beieinander liegen.
Ein weiterer Vorteil dieser Initialverteilungsstrategie ist, daßsie - bis auf das
Verbreiten der Wurzel - ohne jede Kommunikation oder Synchronisation erfolgt.
In der zweiten Phase werden - ausgehend von den Knoten der gespeicherten Suchfront -
die Teilbäume unterhalb dieser Knoten durchsucht.
Dabei bleibt die in der ersten Phase erzeugte Aufteilung der Suchfront über alle
Iterationen erhalten, so daßin jeder Iteration die Suche bei diesen Knoten beginnt.
Ein Prozessor, der alle ,,seine`` Knoten abgearbeitet hat, stellt eine Anfrage
an einen seiner Nachbarprozessoren.
Falls dieser noch unbearbeitete Knoten in seinem Array hält, schickt er einige davon
an seinen Nachbarn zurück, ansonsten leitet er die Anfrage an einen anderen
Prozessor weiter.
Knoten, die während dieser dynamischen Lastverteilung verschickt werden, wechseln
ihren ,,Besitzer``, d.h. sie werden aus dem Array des Versenders gestrichen
und in das Array des Empfängers übernommen.
Hierdurch reduziert sich eine evtl. durch die Initialverteilung entstandene
ungleichmäßige Lastverteilung mit der Zahl der Iterationen [11].
Ein Prozessor, der in seiner Nachbarschaft keine unbearbeiteten Knoten gefunden hat,
beginnt sofort mit der folgenden Iteration, so daßzwischen den Iterationen keine
globale Synchronisation wie etwa in [10] erfolgt![]() .
Hat ein Prozessor einen Lösungsknoten expandiert, so wird dieses den anderen Prozessoren
mitgeteilt, die die Suche sofort abbrechen.
Um die Optimalität dieser Lösung zu garantieren, mußjedoch beachtet werden, daßdie vorherige Iteration komplett bearbeitet wurde.
.
Hat ein Prozessor einen Lösungsknoten expandiert, so wird dieses den anderen Prozessoren
mitgeteilt, die die Suche sofort abbrechen.
Um die Optimalität dieser Lösung zu garantieren, mußjedoch beachtet werden, daßdie vorherige Iteration komplett bearbeitet wurde.
Ein wesentlicher Vorteil des Algorithmus AIDA* liegt darin, daßauch für die parallele Suche die sequentielle Knotenexpansionsroutine verwendet wird. Dieses liefert eine maximale Arbeitsrate und ermöglicht eine einfache Parallelisierung von anderen sequentiellen Anwendungen. Bei dem Stack-Splitting Ansatz mußdie rekursive Knotenexpansionsroutine angepaßt werden, da hier explizit ein Stack zur Verwaltung der Teilprobleme zur Lastverteilung implementiert werden muß.