Implementierung unter PARIX
Next: Ergebnisse
Up: Iterative Tiefensuche
auf einem
Previous: Der Algorithmus AIDA*
Die Implementierung von AIDA* [13] erfolgte auf dem Parsytec GCel des PC unter dem Betriebssystem PARIX.
Als virtuelle Topologien wurden der Ring und der zweidimensionale Torus verwendet.
Aus Effizienzgründen wurden nicht die Bibliotheksroutinen für die asynchrone
Kommunikation verwendet, sondern die asynchrone Kommunikation durch zwei Threads
für jeden Kanal implementiert.
unter dem Betriebssystem PARIX.
Als virtuelle Topologien wurden der Ring und der zweidimensionale Torus verwendet.
Aus Effizienzgründen wurden nicht die Bibliotheksroutinen für die asynchrone
Kommunikation verwendet, sondern die asynchrone Kommunikation durch zwei Threads
für jeden Kanal implementiert.
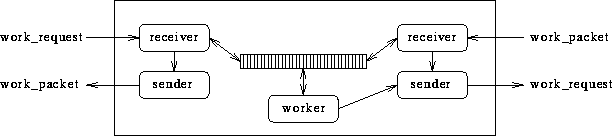
Figure: Das Prozeßmodell für die Implementierung von AIDA* unter PARIX
auf der Ring-Topologie
Abbildung 3 zeigt das Prozeßmodell für die Implementierung
auf der Ring-Topologie.
Der worker- und die receiver-Threads greifen auf das Array mit den Knoten
der gespeicherten Suchfront zu.
Die Kommunikations-Threads (sender und receiver) bearbeiten Arbeitsanfragen
von Nachbarprozessoren bzw. schicken eine Arbeitsanfrage des worker an einen
Nachbarprozessor.
Nachdem alle Prozessoren in der ersten Phase eine Initialverteilung geschaffen haben,
welche - bis auf das Verbreiten der Wurzel - ohne jede Kommunikation erfolgt, beginnen
alle worker im System unabhängig voneinander mit der Suche in den Teilbäumen
unter den Knoten der gespeicherten Suchfront.
Eine erste Phase von wenigen Sekunden liefert eine Initialverteilung, welche die Prozessoren
zu über 90% der Gesamtsuchzeit auslastet, ohne das dynamische Lastverteilung nötig
wird.
Zu Beginn der zweiten Phase hält jeder Prozessor ca. 1000 Knoten.
Hat ein Prozessor alle Knoten aus seinem Array abgearbeitet, so
läßt durch den sender zum rechten Nachbarn auf dem Ring eine
Arbeitsanfrage verschicken.
Die Anfrage bewegt sich auf dem Ring weiter, bis ein Prozessor Arbeit abgeben kann.
Ein solches Arbeitspaket bewegt sich in entgegengesetzter Richtung zum anfragenden
Prozessor zurück.
Konnte kein Prozessor auf dem Ring Arbeit abgeben, so erreicht die Anfrage wieder ihren
Absender, der sofort mit der nächsten Iteration beginnen kann, da im System keine freien
Knoten mehr vorhanden sind.
Es wird dabei bewußt in Kauf genommen, daßnoch Arbeitspakete im Umlauf sein können.
Um dieses festzustellen müßte ein Terminierungserkennungsalgorithmus [1]
verwendet werden.
Da die Paketgröße jedoch beschränkt ist, wird eine Überlappung der Iterationen
unter den einzelnen Prozessoren des Systems toleriert.
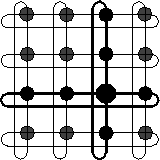
Figure: Die von einem Prozessor bei der
Lastverteilung berücksichtigten Prozessoren auf dem vertikalen bzw. horizontalen Ring
Obwohl dieses Lastverteilungsverfahren auf der Ring-Topologie gute Ergebnisse liefert,
so ist es doch für größere Systeme weniger geeignet, da die Nachrichten am Ende
jeder Iteration sehr weite Wege zurücklegen.
Aus diesem Grund wurde die Implementierung auf die Torus-Topologie übertragen.
Im entsprechenden Prozeßmodell kommen für jeden der beiden zusätzlichen Kanäle
sender- und receiver-Threads hinzu.
Bei der Lastverteilung werden zunächst die Prozessoren auf dem horizontalen Ring
nach dem oben beschriebenen Verfahren berücksichtigt.
Erst wenn auf diesem Ring keine freien Knoten mehr vorhanden sind, wird die Anfrage
auf den vertikalen Ring des Absenders weitergeleitet (siehe Abbildung 4).
Dieses Lastverteilungsverfahren hat sich als sehr effizient erwiesen, da jeder Prozessor
eine andere Menge von 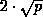 Prozessoren des Systems berücksichtigt.
Eine Überlast wird somit schnell breit über das System verteilt abgebaut und
der Kommunikationsoverhead wächst nicht linear mit der Systemgröße [12].
Prozessoren des Systems berücksichtigt.
Eine Überlast wird somit schnell breit über das System verteilt abgebaut und
der Kommunikationsoverhead wächst nicht linear mit der Systemgröße [12].
Next: Ergebnisse
Up: Iterative Tiefensuche
auf einem
Previous: Der Algorithmus AIDA*
Volker Schnecke
Mon Dec 19 15:48:20 MET 1994