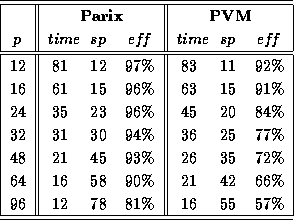
Table 1: GCel transputer system
Tables 1 and 2 show the results obtained
with a subset of Korf's standard random problem instances of the
15-puzzle [7] on the GCel and GC/PP.
For systems with p processors, the total elapsed time,
the speedup sp and the corresponding efficiencies 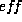 are given.
All times are wall-clock times, measured in seconds.
Speedups and efficiencies are
normalized to the fastest sequential Parix implementation.
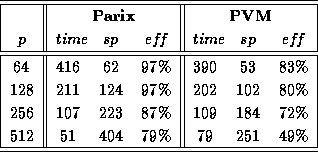
are given.
All times are wall-clock times, measured in seconds.
Speedups and efficiencies are
normalized to the fastest sequential Parix implementation.
With the Parix process model discussed above (Fig. 2),
we achieved on both Parsytec machines an almost perfect scalability
ranging from 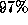 on the `small' systems
to
on the `small' systems
to 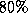 efficiency on the larger networks.
This is a remarkable result, considering that the largest GCel configuration
comprises as many as 512 processors, while the GC/PP has only 96 PEs.
The latter, however, is more powerful, resulting in a much
faster execution speed of only 12 seconds on the largest system.
Clearly, for such short execution runs,
the presented speedups can hardly be improved.
efficiency on the larger networks.
This is a remarkable result, considering that the largest GCel configuration
comprises as many as 512 processors, while the GC/PP has only 96 PEs.
The latter, however, is more powerful, resulting in a much
faster execution speed of only 12 seconds on the largest system.
Clearly, for such short execution runs,
the presented speedups can hardly be improved.
With its 80 MFLOPS peak performance, a single GC/PowerPlus node is expected to be approximately 20 times faster than a GCel-transputer node with its 4 MFLOPS. In this special application, the speedup is even larger: We measured a performance ratio of 26. On the other hand, the communication bandwidth of the GC/PP is only 4 times higher than that of the GCel. Due to the worse communication/computation performance ratio, it is clear, that the 15-puzzle application does not scale as well on the larger GC/PP systems.
Being implemented `on top of Parix', PVM requires some additional CPU-time for the bookkeeping, buffer-copying and function calls. For the larger GCel system, this results in
PVM's availability and portability allowed us to develop our implementations on a workstation cluster, while the production runs were performed on all kinds of parallel systems. We also benchmarked a heterogeneous PVM environment, that allows a collection of serial and parallel computers to appear as a single virtual machine. The task management is done by a PVM daemon running on the UNIX front-end of the parallel system. Since all communication is first checked whether its destination lies `within' or `outside' the MPP system, the heterogeneous PVM cannot be as efficient as the homogeneous PVM discussed above. Performance results for the heterogeneous PVM may be found in [19,22].
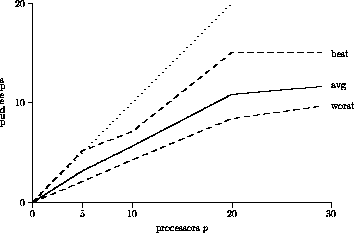
Figure 4: PVM speedup on SUN SS10-cluster, Ethernet
Figure 4 illustrates the performance achieved on a cluster of SUN SparcStation-10. While all workstations are of the same model and speed, the measurements were taken on busy systems with different load factors and a busy Ethernet with several bridges. This results in widely varying execution speeds. Figure 4 shows the average, the slowest and the fastest of 10 runs on the same sample problem set. As can be seen, the initially good speedup seems to level off when more than 20 workstations are employed. The exact data indicates that this is due to the longer start-up times and increased communication latencies.