Previous: N x N--Puzzle
Depth-first search can be performed in parallel by partitioning the search space
into many small, disjunct parts (subtrees) that can be explored concurrently.
We have developed a scheme called
search-frontier splitting [18]
that can be applied to breadth-first-, depth-first- and best-first search.
It partitions the search space into g subtrees that are taken from
a `search-frontier'
containing nodes n with the same cost value 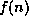 .
Search-frontier splitting has two phases:
.
Search-frontier splitting has two phases:
Search-frontier splitting is a general scheme. It can be employed in depth-first branch-and-bound (DFBB) and in iterative-deepening depth-first search (IDA*). In DFBB, the search continues until all nodes have been either explored or pruned due to inferiority. Newly established bounds are communicated to all processors to improve the local bounds as soon as possible.
In the iterative-deepening variant, AIDA* [18], subsequent iterations are started on the previously established frontier node arrays. Work packets change ownership when they are sent to other processors, thereby improving the global load-balance over the iterations. Lightly loaded processors, which have asked for work in the last iteration will be better utilized in the next. As a consequence, the communication overhead decreases during the search process [18].
Previous: N x N--Puzzle