To determine the appropriate configuration of the feedforward MLP network several parameters have been varied:
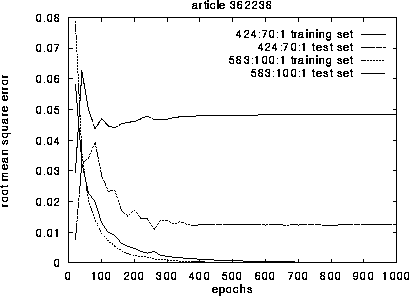
Figure 3: error during training
The given data is split into a training set (week 36/1994 to week 24/1995) and a test set (week 25/1995). The test set is not trained and only considered to check whether the net has generalized the behaviour of the time series. With n=2 we have 39 pairs in the training set and one in the test set, with n=3 we have 38 pairs in the training set and one in the test set.
Several experiments have led to a training rate of 0.25 and a momentum of zero that are best for training and prediction.
Figure 3 shows the root mean square error on the training and test set for n=2 resp. n=3, while learning 1000 epochs of the time series for the article in figure 2 with this parameter settings. The error is going down immediately on the training set, especially for the larger nets.
More important is the error on the test set --- the prediction error. This is better for the net with n=2. It needs more epochs to learn the rule of the time series, but can generalize its behaviour better.
The prediction error of the net 424:70:1 in means of sales can be seen from figures 2, too. For the week 25/1995 the forecasted sale is drawn dotted: the error is smaller than one piece.
The time for training the nets on a sequential SUN SPARC 20 can be seen in table 1.
| net | # training | 1c|time for | |
| topology | 1.5ex[-1.5ex] | pairs | 1c|1000 epochs |
| 424:35:1 | 2 | 39 | 489 sec |
| 424:70:1 | 2 | 39 | 1018 sec |
| 583:50:1 | 3 | 38 | 907 sec |
| 583:100:1 | 3 | 38 | 1815 sec |
Table 1: training times on SPARC 20-50MHz