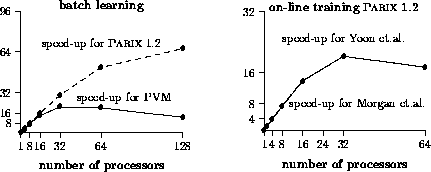
Figure 10: Speed-ups for GCel with T805
The parallel implementations take place on Transputer-based PARSYTEC systems. We use a GCel with T805 and a GC/PP with PowerPC 601 CPUs and Transputer communication links. The parallelization runs with both the runtime environments PARIX Version 1.2 (GCel) resp. 1.3 (GC/PP) and PVM/PARIX 1.1.
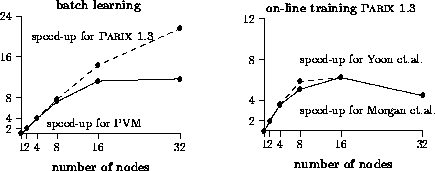
Figure 11: Speed-ups for GC/PP with PowerPC
The figures 10 and 11 show the reached speed-ups with both systems. The results show that the batch learning algorithm scales better than the on-line training. The reason for this are the very high communication demands for each pair trained in contrast to the one communication per epoch for parallel batch learning. As expected the on-line parallelization of Morgan et.al. is worse for small nets and less processors than that of Yoon et.al. according to the uninterrupted communications. This difference vanishes for relatively large number of neurons and processors.
The comparison of both hardware architectures shows that the T805 system scales better than the GC/PP. The computational power of the PowerPC is much higher than that of the T805. But the ratio of the communication and CPU performance is higher on T805 systems.