In the first phase, AIDA* performs a breadth-first search to
expand the same search node frontier on every processor.
The breadth-first search![]() is stopped when a sufficient number of nodes is generated
to give every processor its own fine-grained work packets
for further asynchronous exploration.
In practice, this is not done in a single step,
but an intermediate search frontier is stored on every processor,
so that the more fine-grained work packets can be generated
asynchronously on all processors (for details see [16]).
is stopped when a sufficient number of nodes is generated
to give every processor its own fine-grained work packets
for further asynchronous exploration.
In practice, this is not done in a single step,
but an intermediate search frontier is stored on every processor,
so that the more fine-grained work packets can be generated
asynchronously on all processors (for details see [16]).
At the end of the initial work distribution phase,
each processor `owns' 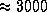 work packets for the 15-puzzle,
when being run on 1024 processors.
work packets for the 15-puzzle,
when being run on 1024 processors.
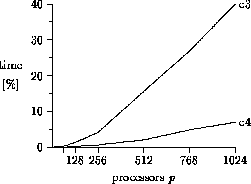
Figure 6: Time of first phase (15-puzzle)
The time spent in the first phase depends on the node expansion time and the
system size, because enough nodes must be generated to keep every processor
busy thereafter.
In the 15-puzzle, three seconds are spent in the first phase on a 1024-node system
[16], resulting in a 40% overhead
of the total elapsed time for the small class 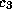 problems
(Fig. 6) on the 1024-node system.
Clearly, AIDA* - and more generally -
our fixed-packet DFS, is ill suited for running small problem instances.
But many other methods
would not work either because they suffer the same initial work
distribution problem.
problems
(Fig. 6) on the 1024-node system.
Clearly, AIDA* - and more generally -
our fixed-packet DFS, is ill suited for running small problem instances.
But many other methods
would not work either because they suffer the same initial work
distribution problem.