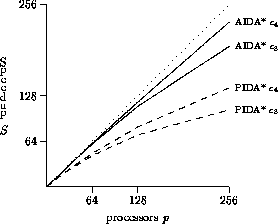
Figure 3: Speedup on a ring (15-puzzle)
Figure 3: Speedup on a ring (15-puzzle)
Figure 3 shows speedup graphs of the 15-puzzle run on a unidirectional ring with up to 256 processors. We selected the ring topology for our experiments, because due to the large communication diameter, it is difficult to achieve good speedups. Algorithms exhibiting good performance on a relatively small ring are likely to run efficiently on much larger networks with a small diameter (torus, hypercube, etc.). As can be seen, this is true for AIDA*, which outperforms PIDA*, especially on the larger networks.
Taking Korf's [6] 100 random 15-puzzle problem instances
and dividing them into four classes 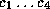 , we run the
50 hardest problems of the classes
, we run the
50 hardest problems of the classes 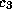 and
and 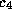 on our transputer system.
Speedup anomalies are eliminated by
normalizing the CPU time results to the number of node expansions.
The data given is the average of the 25 single speedups achieved
in the corresponding problem class.
on our transputer system.
Speedup anomalies are eliminated by
normalizing the CPU time results to the number of node expansions.
The data given is the average of the 25 single speedups achieved
in the corresponding problem class.
In both algorithms, PIDA* and AIDA*,
work requests are forwarded along the ring
until a processor has work to share.
The donor then selects an unsearched node,
deletes it from the stack
(for PIDA*) or frontier node array (for AIDA*)
and sends it in the opposite direction to the requester![]() .
When no processor has work to share, the original work-request
makes a full round through the ring, indicating
that no work is available.
.
When no processor has work to share, the original work-request
makes a full round through the ring, indicating
that no work is available.
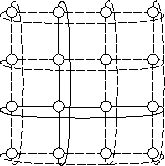
Figure 4: Work-load balancing in fixed-packet DFS
On a torus network,
the work-packets are sent first along the horizontal and then along the vertical
rings, see Fig. 4.
This results in a widespreaded
distribution of the local work-load among the whole system.
Each processor consideres a different subset of
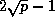 processors.
So the maximum travel-length of the work-packets doesn't increase
lineary with system-size.
processors.
So the maximum travel-length of the work-packets doesn't increase
lineary with system-size.
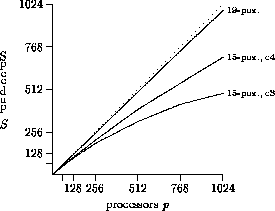
Figure 5: AIDA* speedup on torus topologies
Figure 5 shows the AIDA* performance on torus topologies of
up to 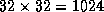 processors.
On this system,
a class problem takes only 7 seconds to solve,
while the larger problem instances take 43 seconds on the average.
processors.
On this system,
a class problem takes only 7 seconds to solve,
while the larger problem instances take 43 seconds on the average.
The topmost graph in Figure 5 illustrates AIDA*'s performance
on the larger 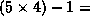 19-puzzle.
Thirteen problem instances have been generated and run on tori
with an average CPU-time of 30 minutes on the 1024-node system.
19-puzzle.
Thirteen problem instances have been generated and run on tori
with an average CPU-time of 30 minutes on the 1024-node system.